تشمل الخدمة الأساسية بناء نموذج تصنيف باستخدام خوارزميات تعلم الآلة الأساسية (مثل Decision Trees, SVM, Logistic Regression, KNN)، مع تنظيف البيانات، استخراج الميزات المهمة، وتحليل دقة النموذج، وذلك لبيانات تصل إلى 50,000 سجل و 20 متغيرًا، مع إمكانية تحسين النموذج وإضافة ميزات متقدمة حسب الطلب
يتم تحليل البيانات لاكتشاف الأنماط والتأكد من جودتها، مع تحديد الميزات الأكثر تأثيرًا في التصنيف لتحسين دقة النموذج
يشمل معالجة القيم المفقودة، إزالة التكرارات، وتحويل البيانات إلى تنسيق مناسب لاستخدامها في خوارزميات التصنيف.
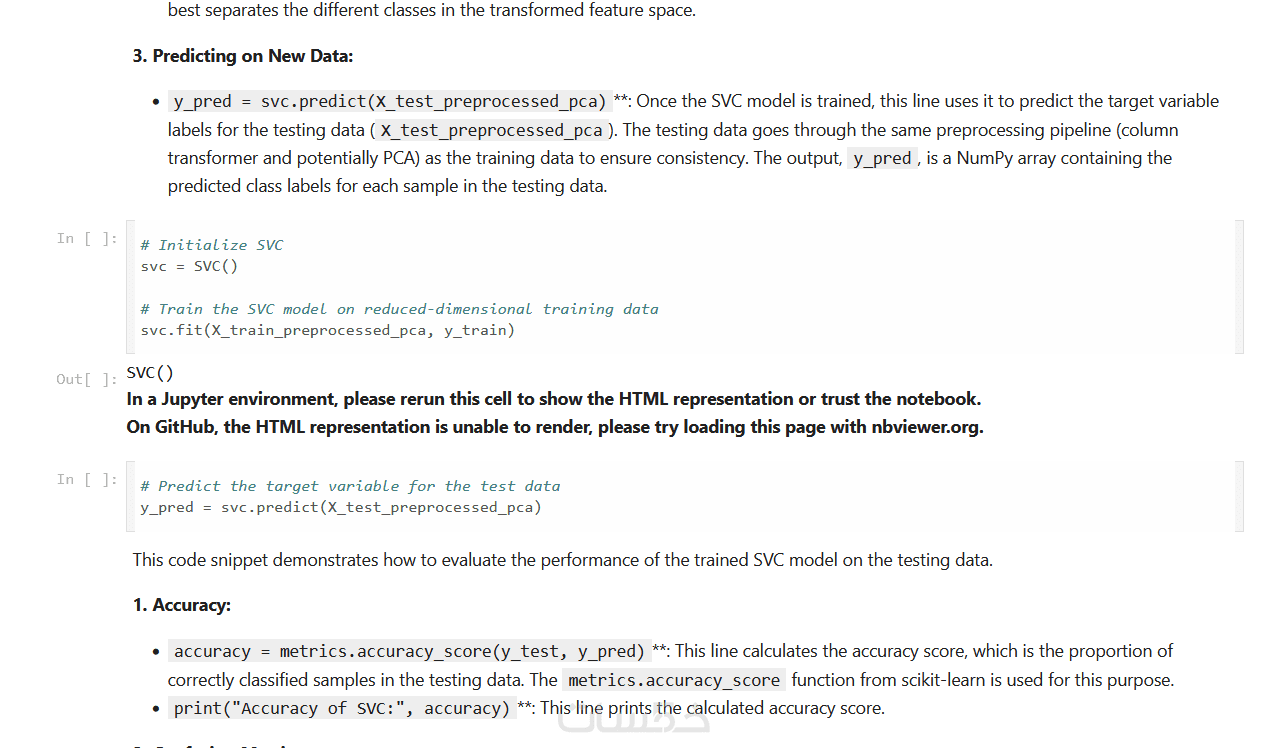
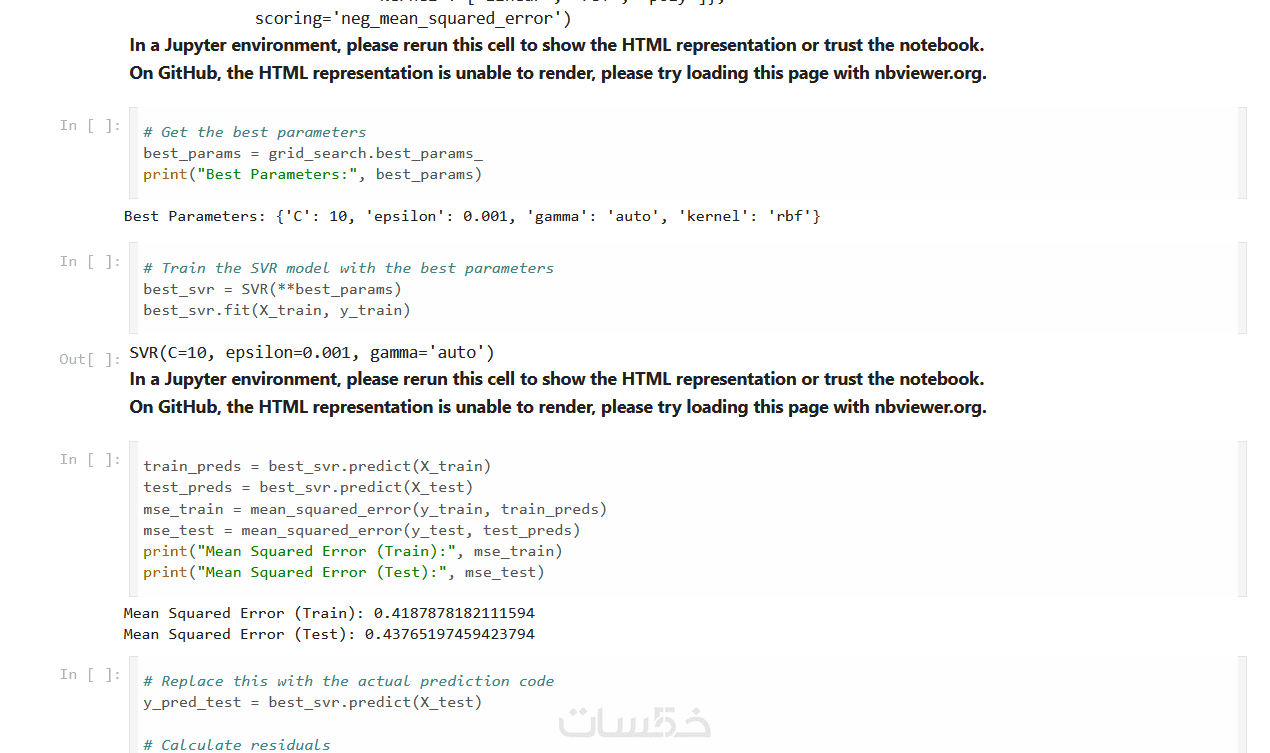
يتم استخدام خوارزميات تصنيف مثل Logistic Regression, Decision Trees, Random Forest, SVM, KNN لاستخراج أفضل النتائج.
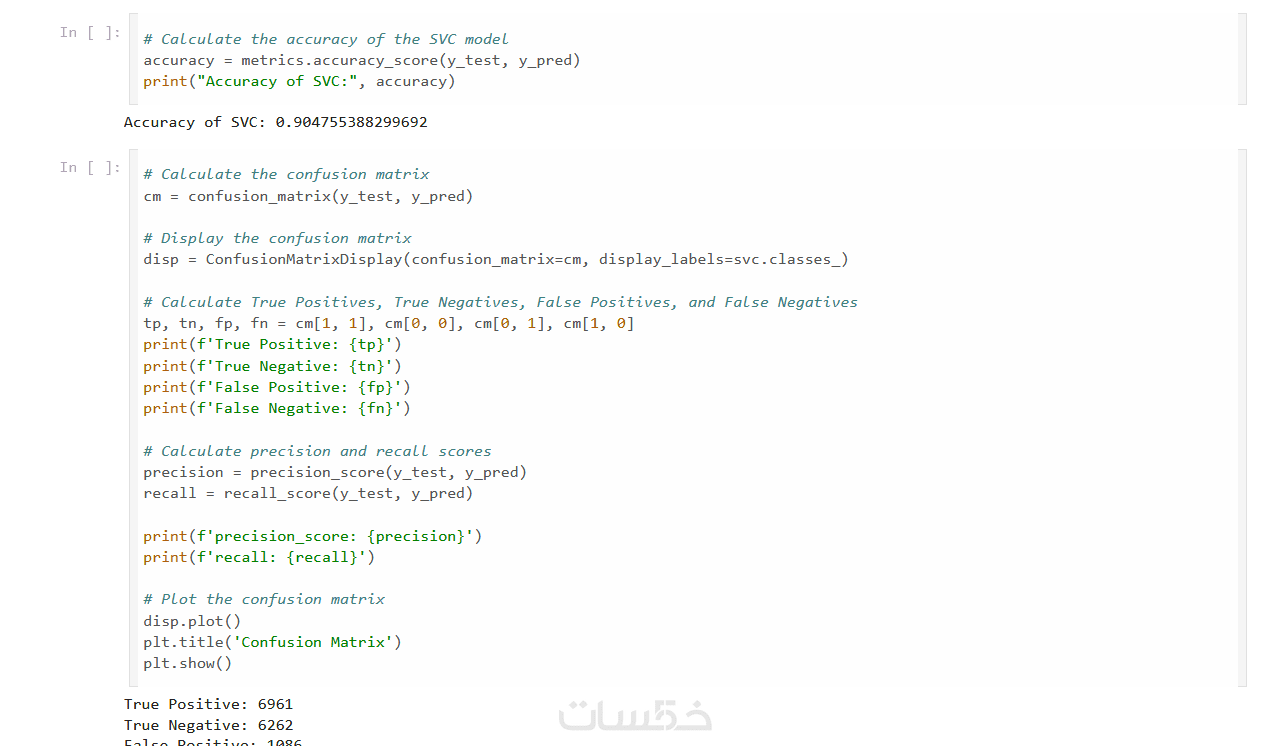
يتم قياس دقة النموذج باستخدام مصفوفة الالتباس (Confusion Matrix)، الدقة (Accuracy)، الاستدعاء (Recall)، والتأكد من كفاءة النموذج.
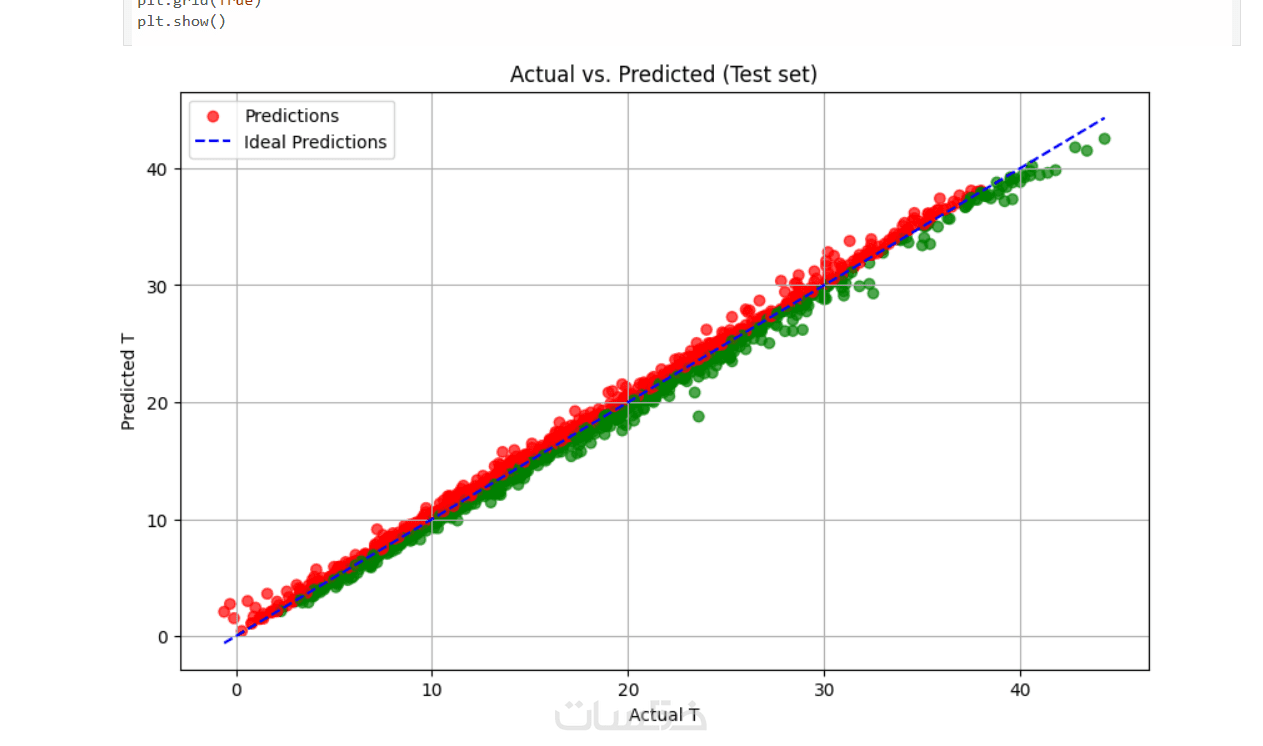
إنشاء رسوم بيانية وتقارير تحليلية لتوضيح أداء النموذج، توزيع البيانات، والعلاقات بين المتغيرات لتحسين الفهم واتخاذ القرار.