تشمل الخدمة تدريب نماذج تعلم عميق (Deep Learning) لتصنيف الصور بدقة، باستخدام شبكات عصبية مثل CNN وResNet، مع إمكانية معالجة البيانات، تحسين جودة الصور، وضبط النموذج لتحقيق أفضل أداء. كما يمكن تقديم تقرير بالنتائج وتحليل دقة النموذج و تدعم الخدمة تصنيف حتى 10,000 صورة في 3-5 فئات باستخدام نموذج جاهز أو معدل، مع إمكانية تخصيص التدريب، تحسين الأداء، وإضافة فئات إضافية حسب الطلب
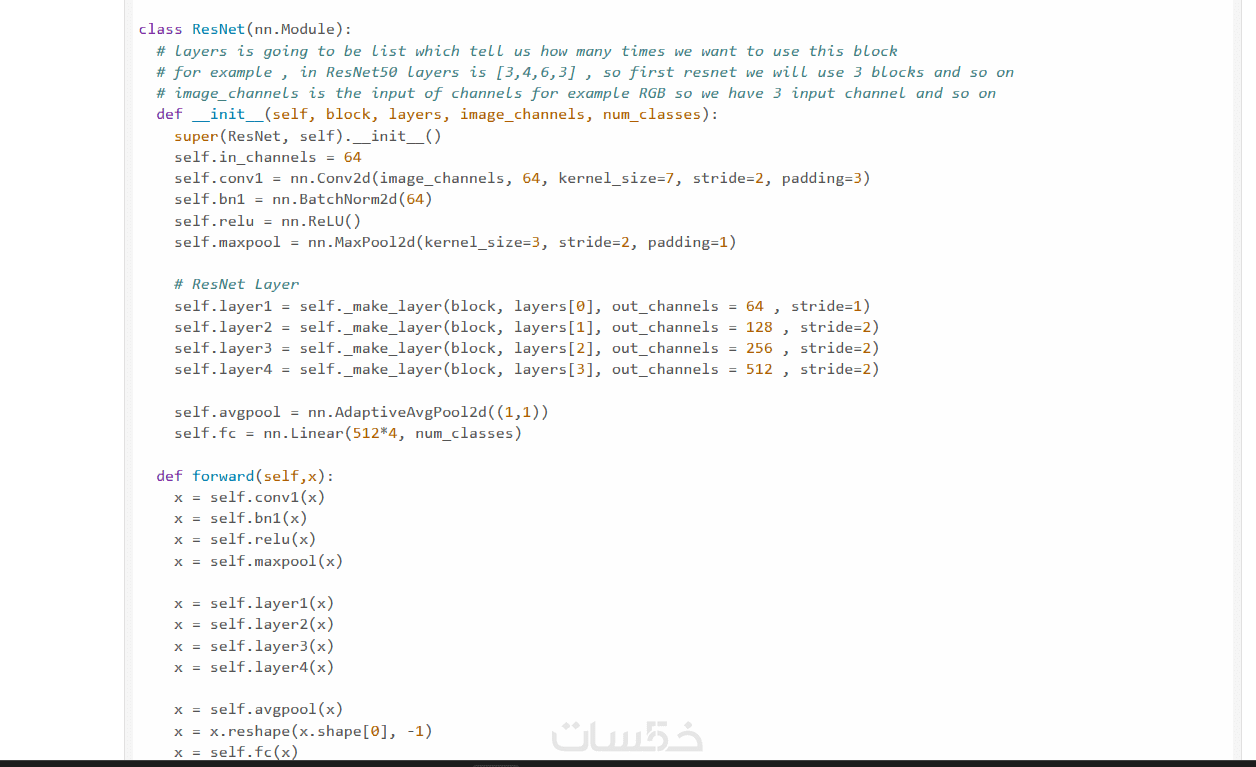
يتم تدريب النموذج باستخدام شبكات عصبية متقدمة (CNN, ResNet, EfficientNet) لضمان دقة تصنيف عالية وتحليل مرئي متطور.
يتم اختبار النموذج على بيانات منفصلة، مع قياس دقة التصنيف، الحساسية (Sensitivity)، والتخصص (Specificity) لضمان أداء موثوق.
تشمل الخدمة تنظيف البيانات، إزالة التشويش، ضبط الألوان، وتطبيع الصور لزيادة دقة النموذج وتقليل الأخطاء.
إمكانية إضافة فئات جديدة، تعديل معمارية النموذج، أو تحسينه عبر نقل التعلم (Transfer Learning) لملاءمة احتياجات المشروع.
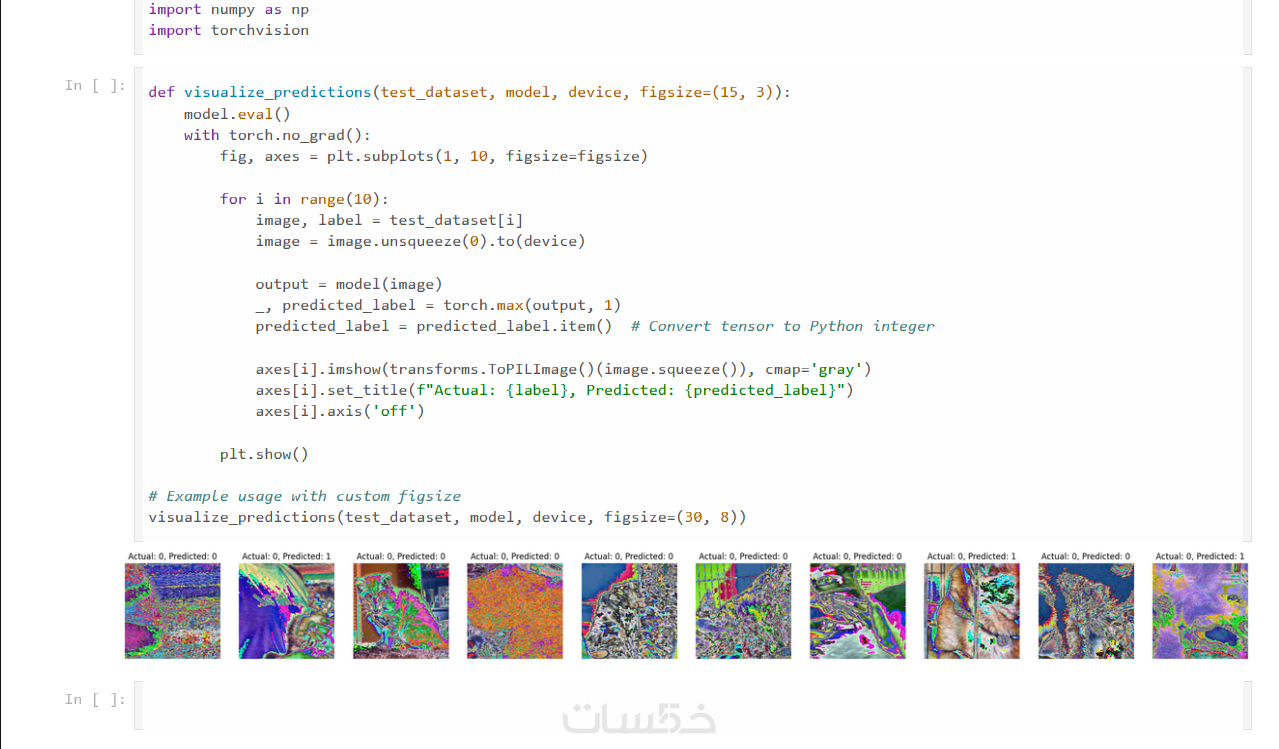
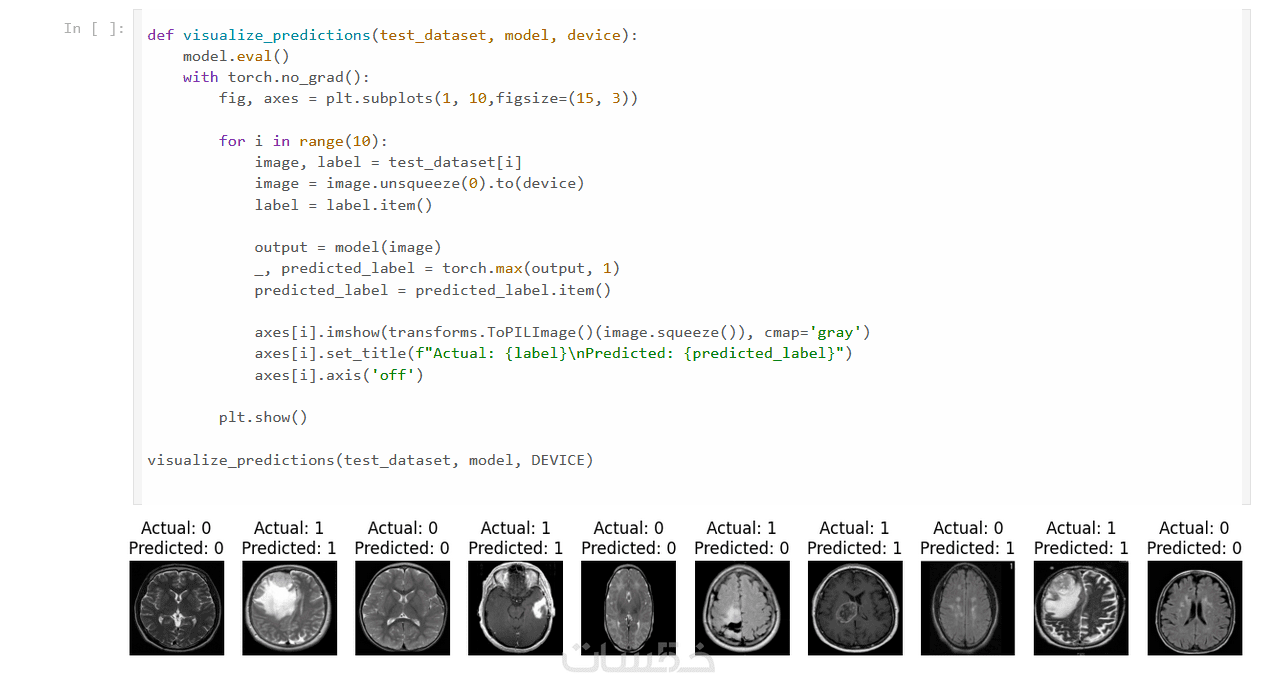
يتم عرض نتائج التصنيف، تحليل الأخطاء، وإنشاء تصورات بيانية (مثل Confusion Matrix وAccuracy Curves) لفهم أداء النموذج بوضوح
يدعم النموذج صور بصيغ متعددة (JPG, PNG, TIFF, BMP) ومجموعات بيانات ضخمة، مع إمكانية معالجة الصور قبل التدريب.