إعداد البيانات Datasets للتحليل والمشاريع عبر panads
إعداد البيانات Datasets للتحليل والمشاريع عبر panads
وصف الخدمة
أقدم لك خدمة احترافية لتنقية ومعالجة مجموعات البيانات (Datasets) باستخدام بايثون لضمان دقة التحليل.
الخدمات التقنية:
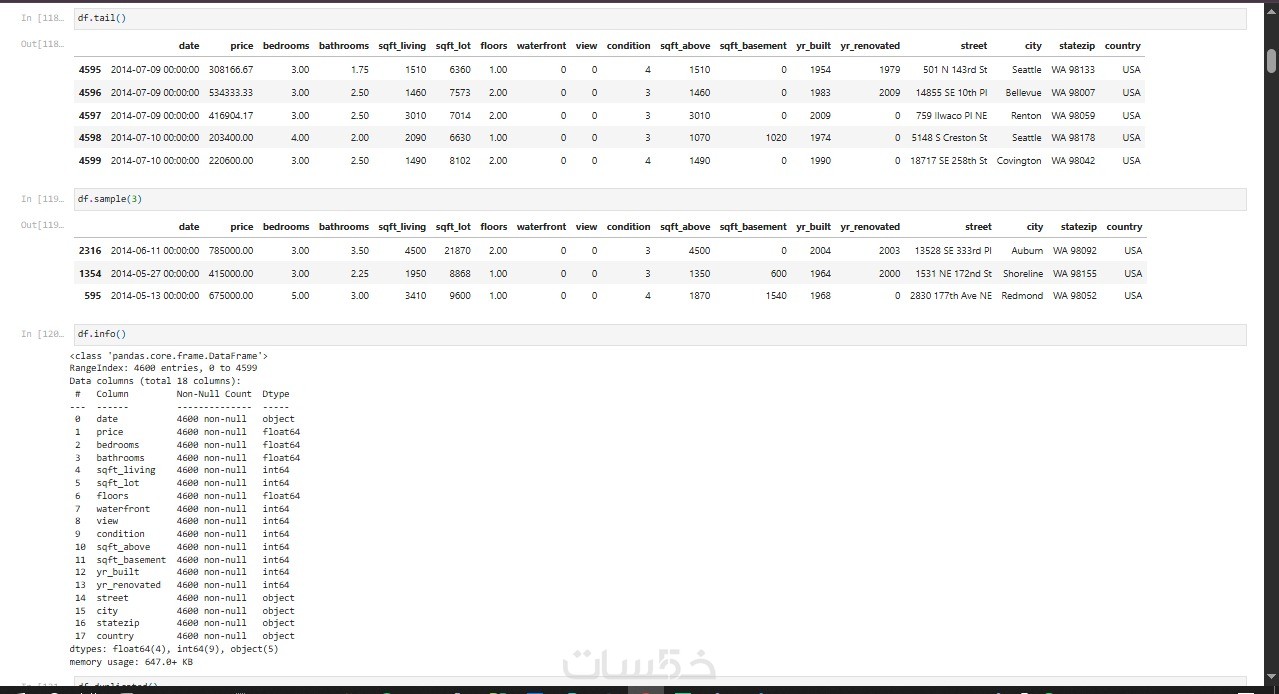
معالجة القيم المفقودة (Handling Missing Data): التعامل مع الفراغات بالملء الإحصائي أو الحذف المنهجي.
إزالة التكرار والتناقض (Removing Duplicates & Outliers): تنقية السجلات ومعالجة القيم المتطرفة.
هيكلة البيانات (Data Standardization): توحيد صيغ التواريخ والنصوص وضبط أنواع البيانات (Data Types).
إعداد البيانات للتعلم الآلي (Feature Engineering): تجهيز الخصائص عبر تقنيات (Scaling & Encoding).
تفاصيل الخدمة الأساسية:
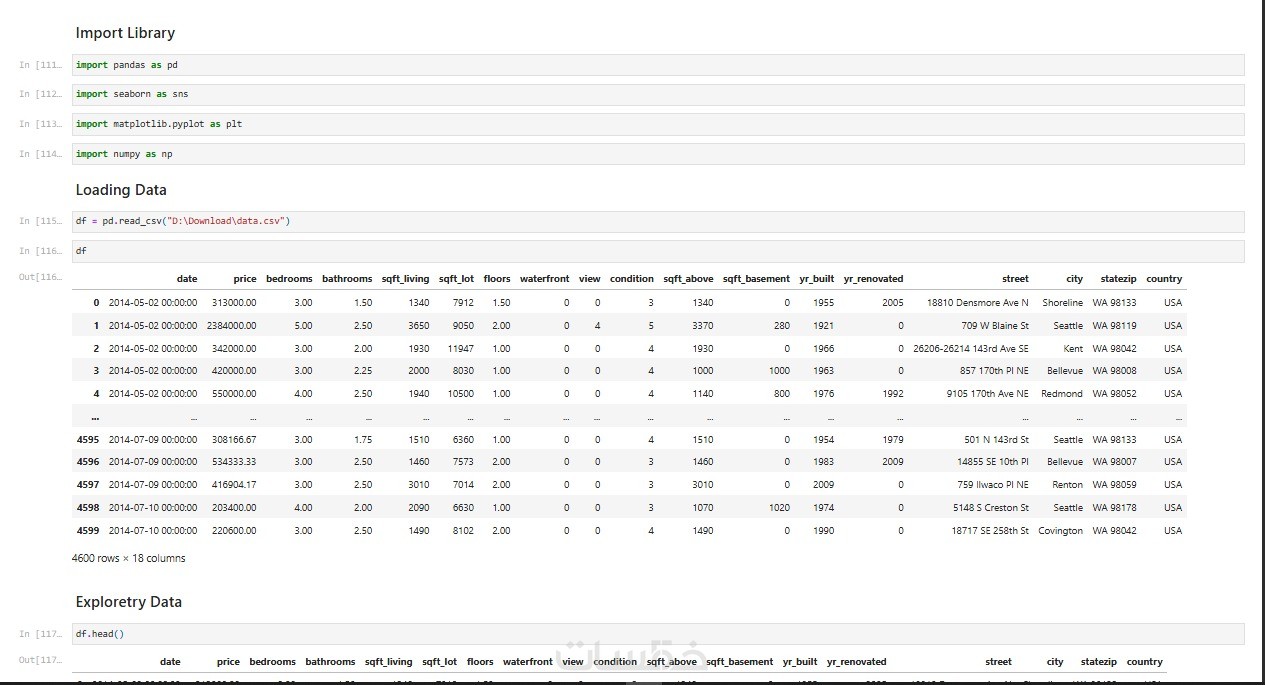
سأقوم بتنظيف ملف بيانات يتراوح حجمه بين 1000 إلى 1500 سطر، وبعدد أعمدة بين 12 إلى 15 عموداً كحد أقصى. يتم تسليم العمل بصيغة Excel أو CSV منظمة وجاهزة للاستخدام.
مميزات الخدمة
(Python & Pandas Powered) المعالجة البرمجية
توظيف قوة مكتبات بايثون وباندز لضمان معالجة آلية دقيقة للملفات الكبيرة بسرعة فائقة، مما يقلل من احتمالية الخطأ البشري في تنظيف البيانات.
(Ready-to-Use Data) جاهزية البيانات
الحصول على مجموعات بيانات مفلترة ومنظمة بالكامل، جاهزة للاستخدام الفوري في التحليلات الإحصائية أو لتغذية نماذج الذكاء الاصطناعي دون الحاجة لأي تعديلات إضافية.
(Versatile Exports) مرونة التصدير
توفير البيانات النهائية بالصيغة التي تتوافق مع بيئة عملك، سواء كانت ملفات Excel للجداول، CSV للأنظمة المختلفة، أو JSON للمشاريع البرمجية.
ما الذي ستستلمه
ملف بيانات نهائي ومنظم
نسخة احترافية من بياناتك بالصيغة التي تفضلها (Excel, CSV, JSON)، بعد خضوعها لعمليات التنقية، المعالجة، وإزالة التكرارات بشكل كامل.
كود برمي نظيف (Clean Code)
ملف البرمجة (Python Script) الذي تم استخدامه في عملية المعالجة، مكتوباً بمعايير برمجية عالية ومنظماً بوضوح لضمان الشفافية وإمكانية إعادة الاستخدام.
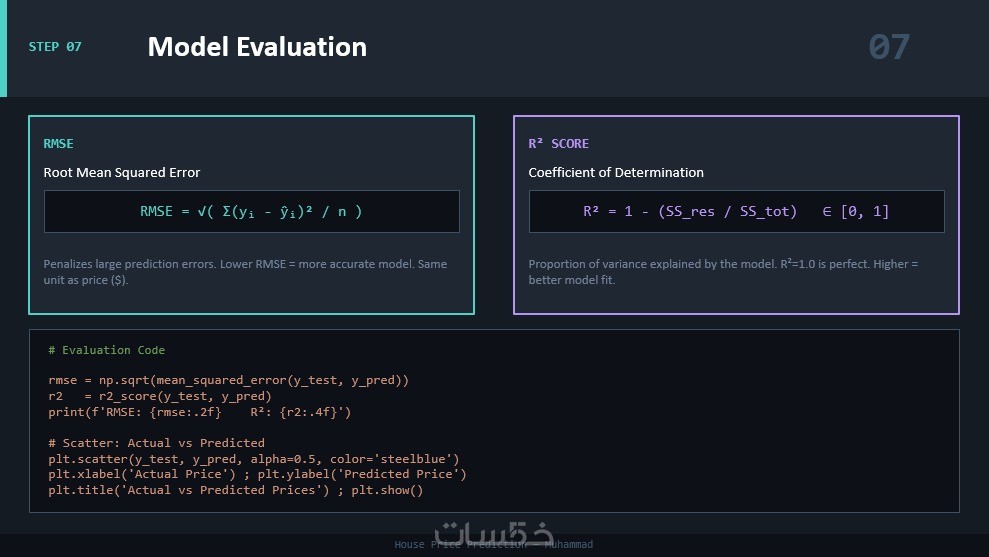
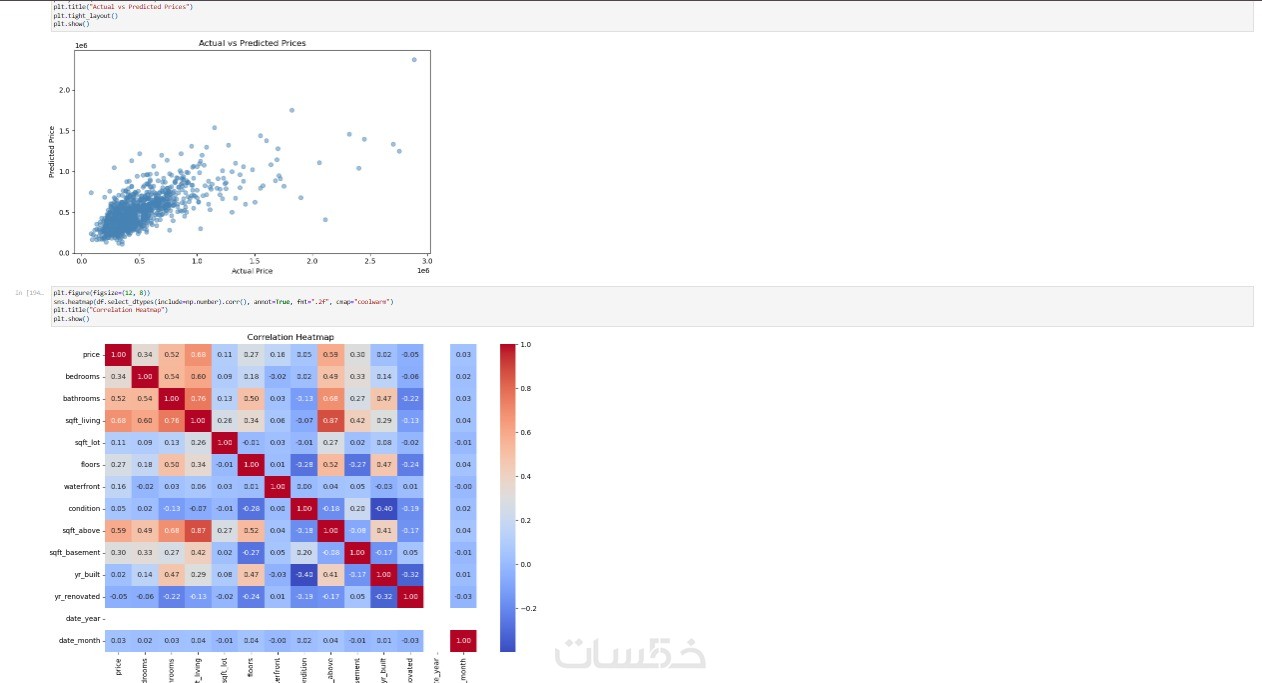
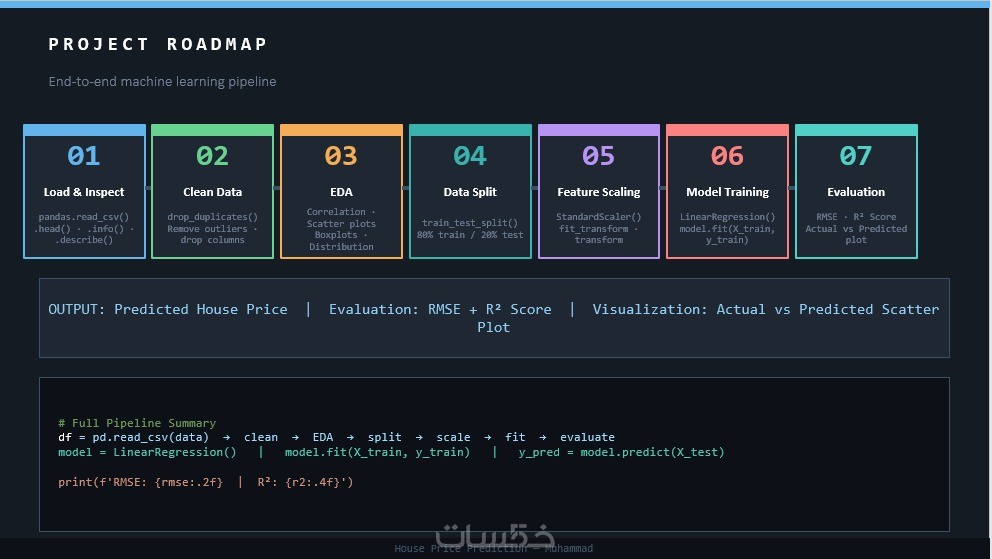
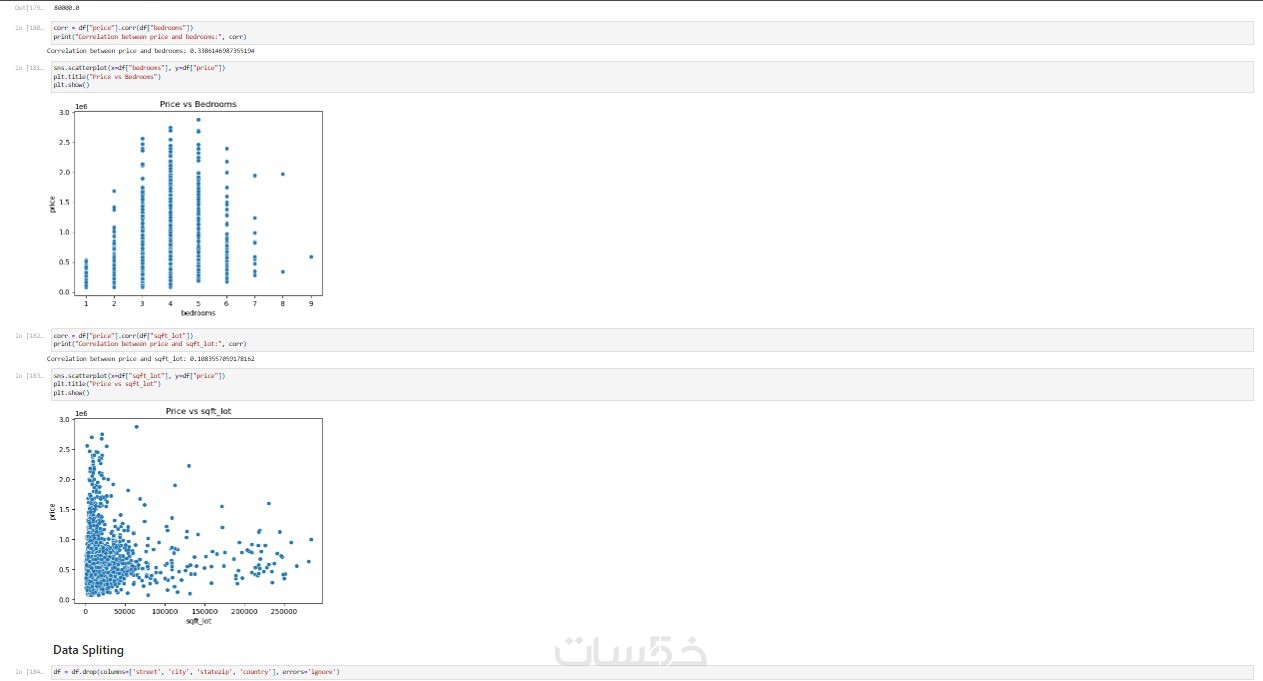
لوحة بيانات بصرية (Data Visualization)
رسوم بيانية توضيحية تلخص حالة البيانات قبل وبعد المعالجة، مما يسهل عليك فهم التوزيعات الإحصائية والنتائج الأولية لمشروعك.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$10.00
خدمات قد تنال إعجابك
كلمات مفتاحية

