انشاء نماذج ذكاء اصطناعي احترافية AI Models
انشاء نماذج ذكاء اصطناعي احترافية AI Models
وصف الخدمة
تطوير نماذج تعلم آلة (Machine Learning) متكاملة وعالية الدقة
أقدم خدمة احترافية لتصميم نماذج ذكاء اصطناعي لتحويل البيانات إلى توقعات دقيقة تساعد على اتخاذ قرارات مبنية على البيانات. تشمل الخدمة بناء Pipeline كامل يبدأ بتحليل البيانات وتنظيفها، معالجة القيم المفقودة والمتطرفة، ترميز المتغيرات الفئوية، توحيد المقاييس، موازنة البيانات عند الحاجة، واستخراج الميزات المهمة. يتم تدريب نموذج قوي باستخدام خوارزميات مثل Random Forest، XGBoost، AdaBoost أو CatBoost، مع ضبط المعاملات لضمان الأداء والاستقرار على بيانات جديدة. التسليم يشمل النموذج، كود منظم، ملف Scaler، وتقرير يوضح أداء النموذج وأهم العوامل المؤثرة.
نطاق ومميزات الخدمة
نطاق الخدمة
تحليل ومعالجة البيانات
استكشاف البيانات (EDA) وفهم العلاقات بين المتغيرات
تنظيف البيانات ومعالجة القيم المفقودة والمتطرفة
Encoding للمتغيرات الفئوية
Standardization أو Normalization
موازنة البيانات عند الحاجة باستخدام SMOTE
Feature Engineering لتعزيز قوة التنبؤ
تطوير النماذج
التصنيف (Classification): تشخيص الأمراض، اكتشاف الاحتيال، تصنيف العملاء
الانحدار (Regression): التنبؤ بالأسعار، توقع الطلب، التنبؤ بالمبيعات
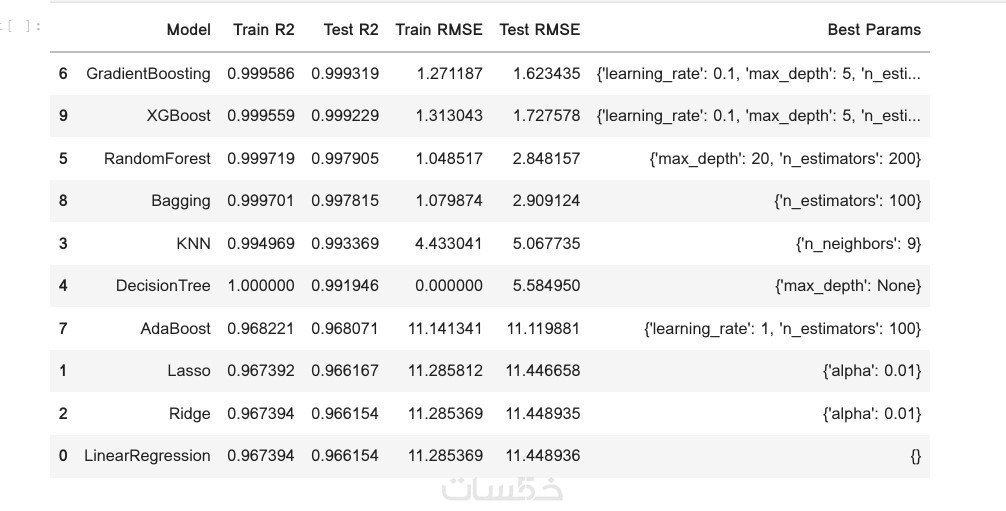
الخوارزميات: Random Forest، XGBoost، AdaBoost، CatBoost
تحسين الأداء والتسليم النهائي
تحسين الأداء عبر Hyperparameter Tuning وCross Validation
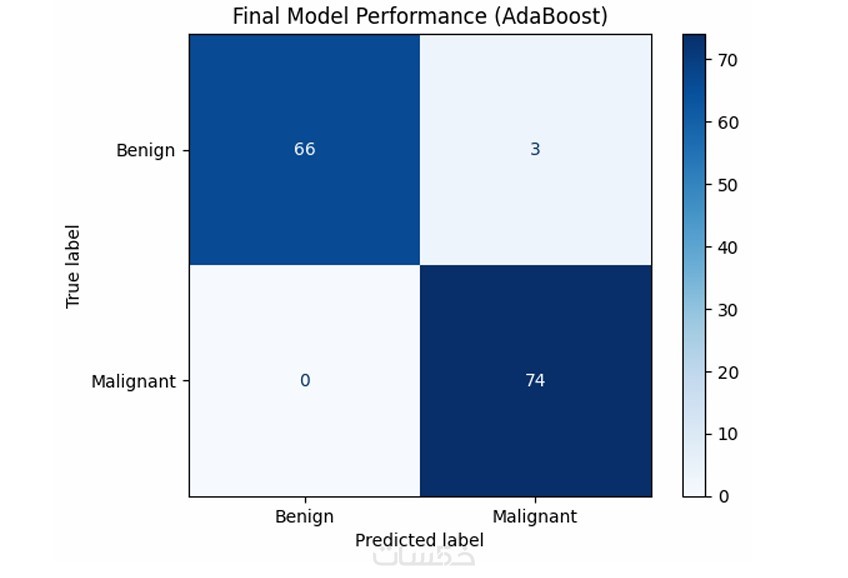
رفع دقة النموذج باستخدام مقاييس مثل Accuracy، Precision، Recall، F1 Score، MAE وRMSE
تقليل Overfitting لضمان أداء قوي على بيانات جديدة
التسليم يشمل:
نموذج جاهز للاستخدام بصيغة Pickle (.pkl) أو Joblib (.joblib)
ملف Scaler المستخدم في التقييس
كود منظم وقابل للتعديل
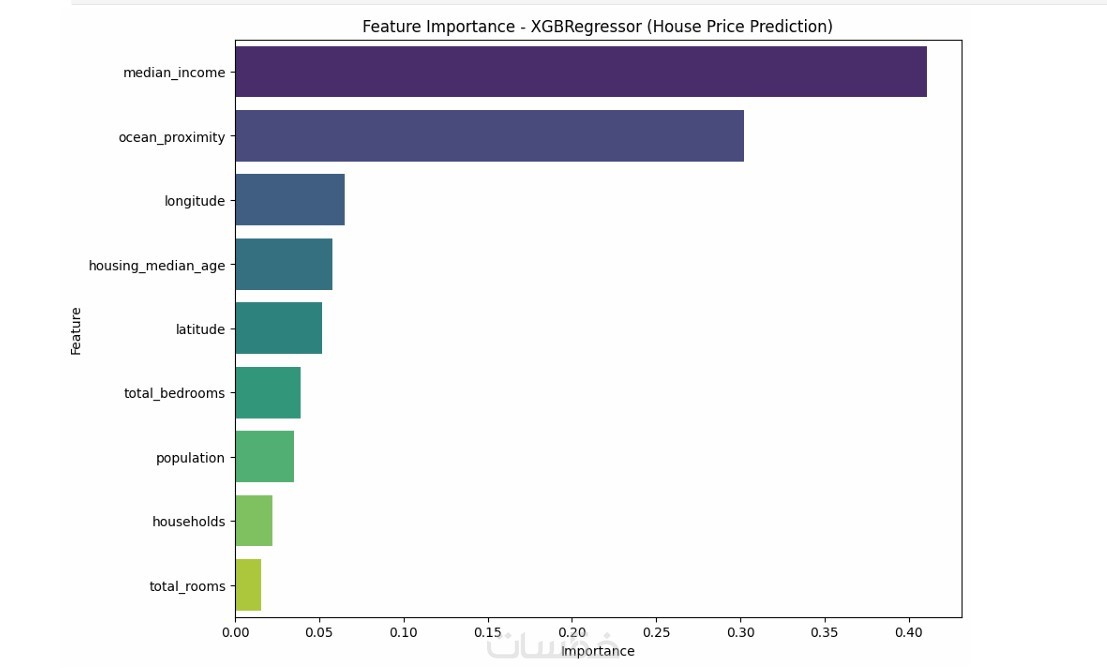
تقرير يوضح أداء النموذج وأهم المتغيرات المؤثرة (Feature Importance)
مميزات الخدمة
نموذج عالي الدقة مبني وفق أفضل ممارسات علم البيانات
تحسين التوازن بين Precision و Recall لتقليل الأخطاء الحرجة
استخدام تقنيات Feature Engineering لاستخراج أقصى قيمة من البيانات
معالجة عدم توازن البيانات باستخدام SMOTE عند الحاجة
الاعتماد على خوارزميات قوية مثل XGBoost و Random Forest و CatBoost
نموذج جاهز للدمج بسهولة داخل التطبيقات أو الأنظمة
توفير تقرير يوضح أهم المتغيرات المؤثرة في التنبؤ
ضمان استقرار الأداء باستخدام Cross Validation
حجم العمل في الخدمة الأساسية
تطوير نموذج تعلم آلة متكامل من البداية للنهاية
تحليل البيانات وتنظيفها ومعالجة القيم المفقودة والمتطرفة
Feature Engineering لاستخراج أهم المتغيرات المؤثرة
تدريب النموذج باستخدام خوارزميات قوية مع تحسين الأداء وضبط المعاملات
التعامل مع بيانات حتى 50,000 صف و50 عمود
تسليم النموذج بصيغة جاهزة للاستخدام
كود منظم وقابل للتعديل بسهولة
تقرير مختصر يوضح أداء النموذج وأهم العوامل المؤثرة
توفير تعديلات بعد التسليم لضمان رضاك الكامل
لماذا تختار هذه الخدمة
نموذج تعلم آلة دقيق وموثوق مبني وفق أفضل ممارسات علم البيانات
تقليل الأخطاء الحرجة مثل False Negatives
تحسين مقاييس الأداء مثل Precision و Recall
معالجة كاملة للبيانات بما في ذلك القيم المفقودة والمتطرفة
استخدام تقنيات Feature Engineering و SMOTE لتعزيز قوة التنبؤ
جاهزية النموذج للدمج بسهولة داخل التطبيقات أو الأنظمة
تقرير يوضح أهم المتغيرات المؤثرة في النتائج
ضمان استقرار الأداء باستخدام Cross Validation
نموذج قابل للتفسير ويوفر رؤى عملية ودقيقة
المتابعة معك حتى بعد تسليم العمل
كلمات مفتاحية
خدمات قد تنال إعجابك













شراء الخدمة
سعر الخدمة
$10.00
خدمات قد تنال إعجابك
كلمات مفتاحية

