تطوير نظام RAG احترافي باستخدام LLM وربطه ببياناتك الخاصة
تطوير نظام RAG احترافي باستخدام LLM وربطه ببياناتك الخاصة
وصف الخدمة
هل تمتلك ملفات، مستندات، أو قاعدة بيانات خاصة بمشروعك وتود أن يجيب الذكاء الاصطناعي على أسئلة عملائك أو موظفيك بناءً عليها فقط بدقة واحترافية؟
الآن يمكنك الاستفادة من القوة الجبارة لنماذج اللغات الكبيرة (LLMs) مثل GPT وغيرها، وتخصيصها لتعمل كخبير في مجالك عبر تقنية RAG (Retrieval-Augmented Generation). هذه التقنية تضمن لك استخراج الإجابات من بياناتك أنت فقط، مما يقضي تماماً على مشكلة "الهلوسة" (Hallucination) التي تقع فيها النماذج العادية.
مميزات الخدمة
دقة متناهية وانعدام "الهلوسة" (Zero Hallucination)
يقدم النظام إجابات دقيقة ومستمدة حصرياً من ملفاتك وبياناتك الخاصة. نضمن لك عدم قيام نموذج الذكاء الاصطناعي بتأليف أو اختراع أي معلومات خارجية، مما يجعله مستشاراً موثوقاً وآمناً لعملك.
فهم عميق للسياق عبر البحث الدلالي (Semantic Search)
بفضل الاعتماد على أحدث تقنيات معالجة اللغات الطبيعية وتحويل النصوص إلى متجهات (Vector Embeddings)، يتجاوز النظام مجرد البحث التقليدي عن الكلمات المفتاحية ليفهم المعنى الحقيقي والسياق وراء سؤال المستخدم، مما يضمن استخراج أدق التفاصيل من مستنداتك.
كود برمجي احترافي وقابل للتطوير (Clean & Scalable Code)
لن تحصل على مجرد حل برمجي مؤقت، بل ستحصل على كود نظيف، منظم، وموثق. هذا يسهل عليك مستقبلاً توسيع النظام، استيعاب حجم بيانات أضخم، أو ربطه بواجهات مستخدم (UI) أو تطبيقات خارجية بسهولة.



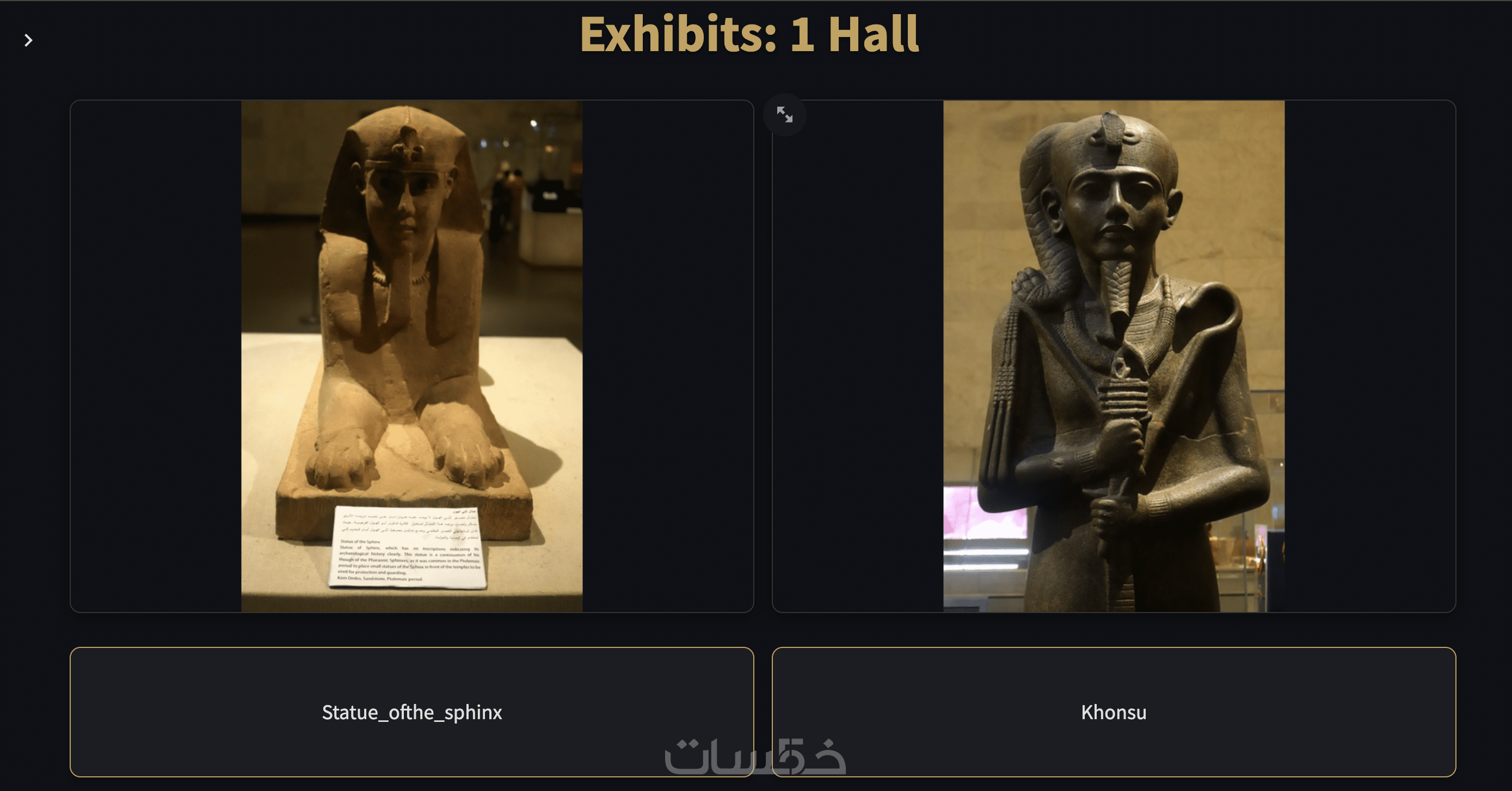
ما الذي ستستلمه
مواصفات التطبيق الأساسي
برمجة وتطوير نظام RAG متكامل وربطه بنموذج لغوي (LLM) وقاعدة بيانات متجهية (Vector DB)، مخصص لمعالجة مستند بيانات واحد (مثال: ملف PDF أو Word بحد أقصى 10 صفحات / أو ما يعادل 3000 كلمة).
عدد الواجهات
سيتم تسليم واجهة مستخدم واحدة (1 Interface) تفاعلية واحترافية تشبه واجهة ChatGPT، لتتمكن من خلالها من توجيه الأسئلة للنظام والحصول على الإجابات مباشرة.
نوع الملفات التي سيتم تسليمها
ستستلم الكود المصدري النظيف (Source Code) داخل ملف مضغوط (يحتوي على الأكواد البرمجية بصيغة .py)، بالإضافة إلى رابط (URL) للوصول للنظام واستخدامه، وملف إرشادات (PDF) يوضح كيفية التشغيل والإدارة.
عدد النسخ والتعديلات
تتضمن الخدمة الأساسية تسليم نسخة واحدة من النظام تعمل بكفاءة، مع أحقيتك في طلب تعديلين (2) على شكل الواجهة أو على دقة استرجاع البيانات قبل الاعتماد النهائي.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$10.00
تطويرات اختيارية
واجهة استخدام (UI) باستخدام Streamlit - HTML - CSS
10.00
|
|
التعديل الشامل لل Backend ( استقرار JSON )
150.00
|
|
تطوير محرك ال PDF ليدعم اللغة العربية بالكامل
40.00
|


شراء الخدمة
سعر الخدمة
$10.00
تطويرات اختيارية
واجهة استخدام (UI) باستخدام Streamlit - HTML - CSS
10.00
|
|
التعديل الشامل لل Backend ( استقرار JSON )
150.00
|
|
تطوير محرك ال PDF ليدعم اللغة العربية بالكامل
40.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
