سأقوم بمعالجة Dataset غير المتوازن باستخدام تقنيات Sampling
سأقوم بمعالجة Dataset غير المتوازن باستخدام تقنيات Sampling
وصف الخدمة
هل بياناتك غير متوازنة وكل نموذج تدربه يتجاهل الفئة المهمة؟
هل الـ Model يتنبأ خطأ في كل مرة لأن 99% من بياناتك غير متوازنه؟
أنا هنا لأحل هذه المشكلة تحديداً
سأقوم ببناء Pipeline متكامل لمعالجة مشكلة اختلال توازن البيانات (Class Imbalance) في مشروعك، باستخدام أحدث تقنيات الـ Sampling
المتعارف عليها في مجال Machine Learning.
مناسبة بشكل خاص لمشاريع كشف الاحتيال، التشخيص الطبي، وأي مشكلة تعاني من نسب اختلال شديدة تصل إلى 750:1
خطوات الـ Pipeline المنفذة:
1. تقسيم البيانات مع الحفاظ على نسبة كل فئة في Train/Test
2. تقليل الفئة الأكبر بذكاء بدلاً من الحذف العشوائي
3. تنظيف الحدود الفاصلة بين الفئتين من الحالات المتداخلة
4. توليد عينات اصطناعية للفئة الأقل تمثيلاً
5.تطبيع الـ Features لتحسين أداء النموذج
التقنيات المستخدمة:
Python 3
imbalanced-learn · Scikit-learn
Pandas
NumPy
Matplotlib / Seaborn
كود منظم وموثق مع شرح كل خطوة
مميزات الخدمة
حجم الـ Dataset بحد اقصى 500k صف
دعم جميع أنواع اختلال التوازن (ثنائي / متعدد الفئات)
Pipeline جاهز للدمج مباشرة في نموذجك
تقرير مقارنة قبل وبعد الـ Sampling مع رسوم بيانية
شرح كامل لكل قرار تقني تم اتخاذه باستخدام التعليقات داخل الكود
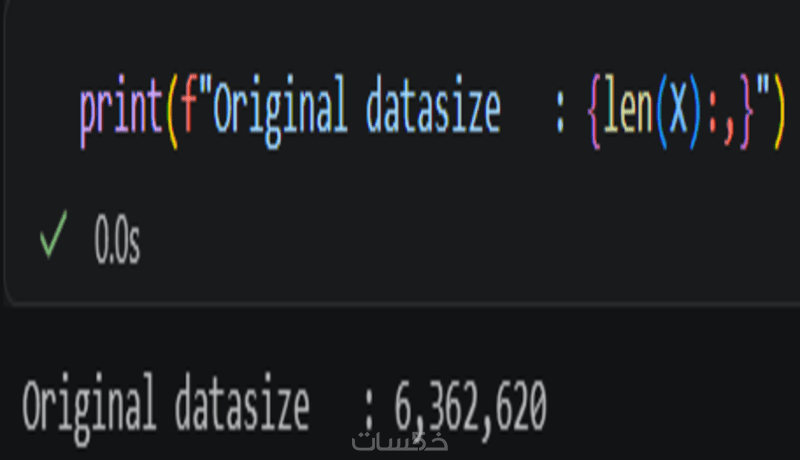

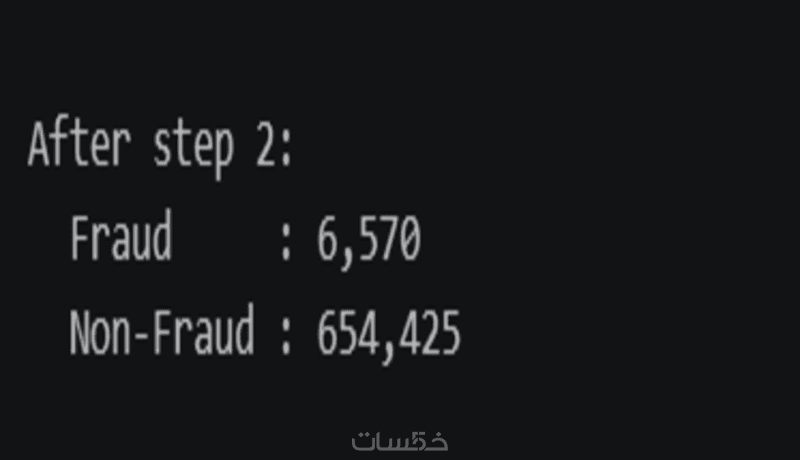

ما الذي ستستلمه
ملف Python جاهز للتشغيل ipynb
ملفات البيانات بعد المعالجة
قرير مقارنة قبل وبعد الـ Sampling
مراجعتان مجانيتان بعد التسليم
كلمات مفتاحية
خدمات قد تنال إعجابك










شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف البيانات بحجمها المختار (500K,750K,1M) صف قبل تطبيق ال sampling
10.00
|
|
رفع الحد الاقصى ألى 750k
5.00
|
|
رفع الحد الاقصى ألى 1M صف
10.00
|
|
اجتماع فيديو عبر zoom او teams بحد اقصى 60 دقيقة لشرح ال code
5.00
|


شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف البيانات بحجمها المختار (500K,750K,1M) صف قبل تطبيق ال sampling
10.00
|
|
رفع الحد الاقصى ألى 750k
5.00
|
|
رفع الحد الاقصى ألى 1M صف
10.00
|
|
اجتماع فيديو عبر zoom او teams بحد اقصى 60 دقيقة لشرح ال code
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
