نظام لوصف الصور تلقائيا Image Captioning بالذكاء الاصطناعي
نظام لوصف الصور تلقائيا Image Captioning بالذكاء الاصطناعي
وصف الخدمة
خدمة تطوير أنظمة وصف الصور (Image Captioning) باستخدام تقنيات التعلم العميق الحديثة، حيث يتم تحويل محتوى الصورة إلى نصوص وصفية دقيقة تشبه الوصف البشري.
تعتمد الخدمة على دمج عدة نماذج متقدمة، منها:
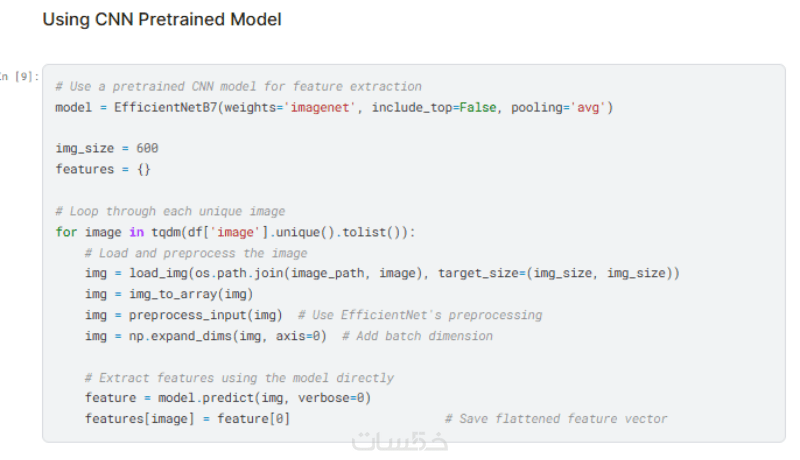
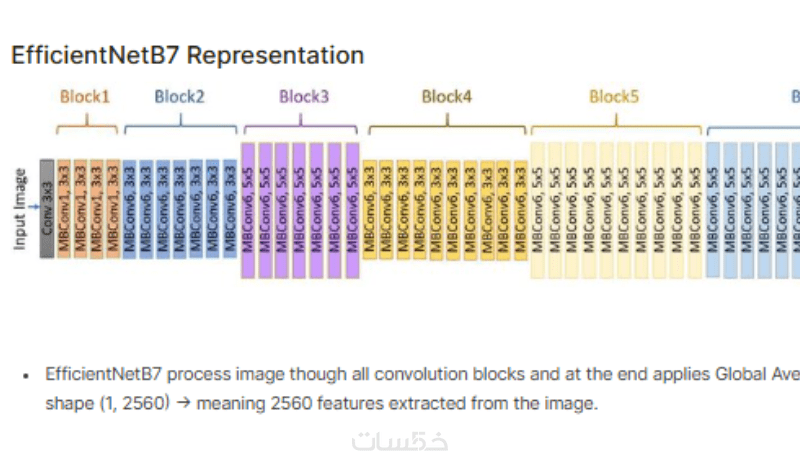
- استخدام شبكات CNN مثل ResNet أو VGG لاستخراج الخصائص البصرية من الصور.
- استخدام نموذج LSTM لتوليد النصوص بشكل تسلسلي.
- تطبيق آلية الانتباه (Attention Mechanism) لتمكين النموذج من التركيز على الأجزاء المهمة من الصورة أثناء توليد كل كلمة.
مميزات الخدمة
توليد وصف طبيعي للصور
يقوم النموذج بكتابة جمل وصفية دقيقة تعبّر عن محتوى الصورة بأسلوب قريب من الوصف البشري
آلية الانتباه (Attention)
تساعد في تحسين جودة النتائج من خلال التركيز على مناطق محددة من الصورة أثناء التوليد
بنية متقدمة (CNN + LSTM + Attention)
دمج فعال بين استخراج الخصائص وفهم التسلسل اللغوي للحصول على أفضل أداء
دعم اللغتين العربية والإنجليزية
إمكانية تدريب النموذج على أي لغة بشرط توفر بيانات مناسبة (حالياً يتم العمل على الإنجليزية مع إمكانية التوسعة للعربية)
قابل للتطبيق على مختلف المجالات
يمكن استخدام النموذج على صور الطبيعة، المنتجات، الطب، السيارات، وغيرها
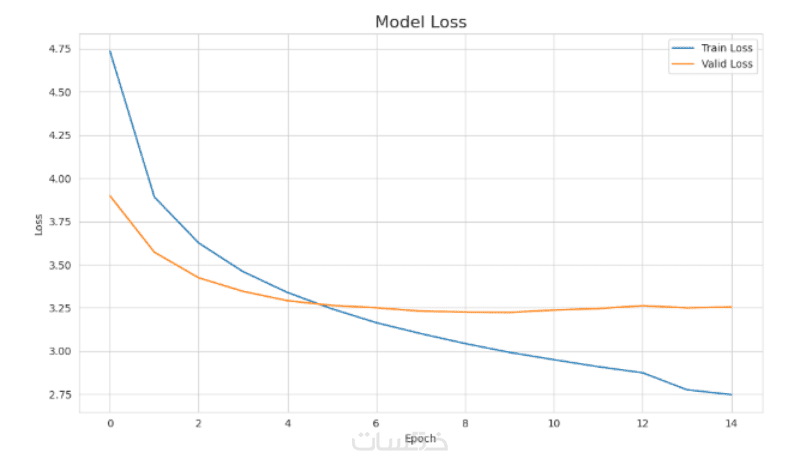
تقييم الأداء بدقة
باستخدام مقاييس عالمية مثل:
BLEU Score
METEOR
CIDEr
معالجة متكاملة للنصوص
تشمل:
- تنظيف البيانات
- Tokenization
- Padding
- بناء قاموس الكلمات تلقائياً
تسليم كامل للمشروع
يشمل نموذج مدرب + كود + أمثلة تطبيقية
متطلبات العمل
لضمان أفضل نتائج، يجب توفير البيانات التالية:
عدد الصور: من 8000 إلى 10000 صورة على الأقل
صيغة الصور: JPG أو PNG
ملف captions بصيغة CSV أو JSON
لكل صورة: من 3 إلى 5 جمل وصفية
يفضّل أن تكون الصور بحجم 224×224 أو 256×256

ما الذي ستسمله
نموذج Image Captioning أساسي
ستحصل على:
تدريب نموذج باستخدام:
من 1000 إلى 3000 صورة كحد أقصى (ضمن الباقة الأساسية)
استخدام:
- CNN لاستخراج خصائص الصور
- LSTM لتوليد النصوص
عدد Epochs للتدريب: من 10 إلى 20 Epoch
زمن تدريب تقريبي: من 1 إلى 3 ساعات حسب الجهاز
توليد وصف (Captions) لعدد: 3 إلى 10 صور جديدة كاختبار عملي
كود Python كامل (Jupyter Notebook)
كود منظم يحتوي على:
- تحميل البيانات
- معالجة الصور والنصوص
- بناء النموذج
- التدريب والتقييم
قابل للتشغيل مباشرة والتعديل
شرح مبسط داخل الكود
يشمل شرحًا واضحًا لـ:
- تجهيز الصور
- Tokeniztion و Padding
- بناء النموذج
- التدريب
- اختبار النموذج
كلمات مفتاحية
خدمات قد تنال إعجابك













طلب الخدمة
سعر الخدمة
$5.00
خدمات قد تنال إعجابك
كلمات مفتاحية

