التحقق من الأسماء العربية باستخدام تقنية التضمين الكلامي


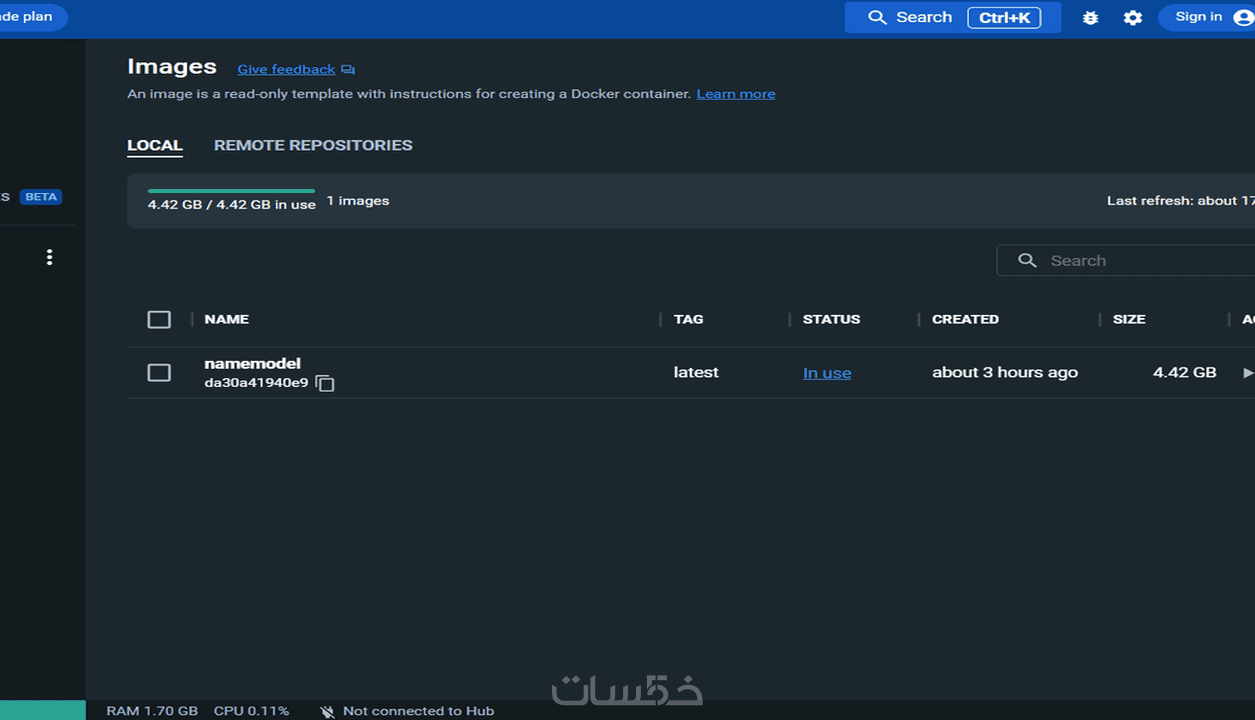
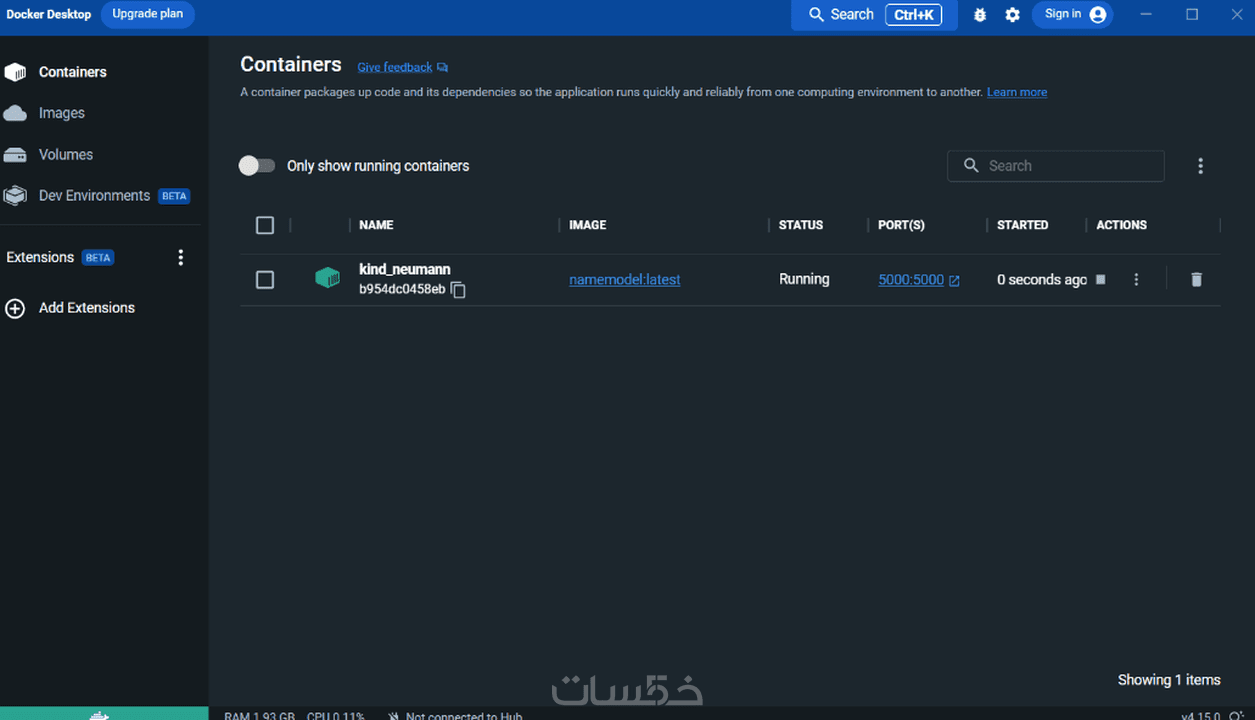


نقدم نموذجًا مبتكرًا يستخدم تقنية التضمين الكلامي لتصنيف الأسماء (حقيقية أو مزيفة) بدقة تصل إلى 99%. يتضمن النهج استخدام تضمينات الكلمات لتمثيل الأسماء وتمييز الأسماء الحقيقية من المزيفة. لتحسين البيانات، تم خلط 30% من البيانات الفعلية لتوليد أسماء مزيفة لأغراض التدريب والاختبار. تم نشر النموذج النهائي باستخدام Flask و Docker.
مميزات الخدمة (مواصفات):
دقة عالية تصل إلى 99% في تصنيف الأسماء كحقيقية أو مزيفة.
استخدام تقنية التضمين الكلامي لتمثيل الأسماء وتمييزها.
إمكانية توسيع وتكامل النظام بسهولة باستخدام Flask و Docker.
عدد البيانات:
تحضير وتجميع مجموعة بيانات تحتوي على ما بين 5000 إلى 10000 سجل لكل جدول.
حجم البيانات:
يمكن أن يتراوح حجم مجموعة البيانات من 50 ميجابايت إلى 1 جيجابايت، اعتمادًا على عدد البيانات وتعقيد النموذج.
يرجى ملاحظة أن هذه الأرقام قابلة للتعديل بحسب احتياجاتك ومتطلبات المشروع.

اشتري الخدمة
مرات الطلب
المبلغ
10$
خدمات مقترحة


















كلمات مفتاحية
