تحليل بيانات الرعاية الصحية
تحليل بيانات الرعاية الصحية
عن الخدمة
1. فهم البيانات:
استعراض البيانات:
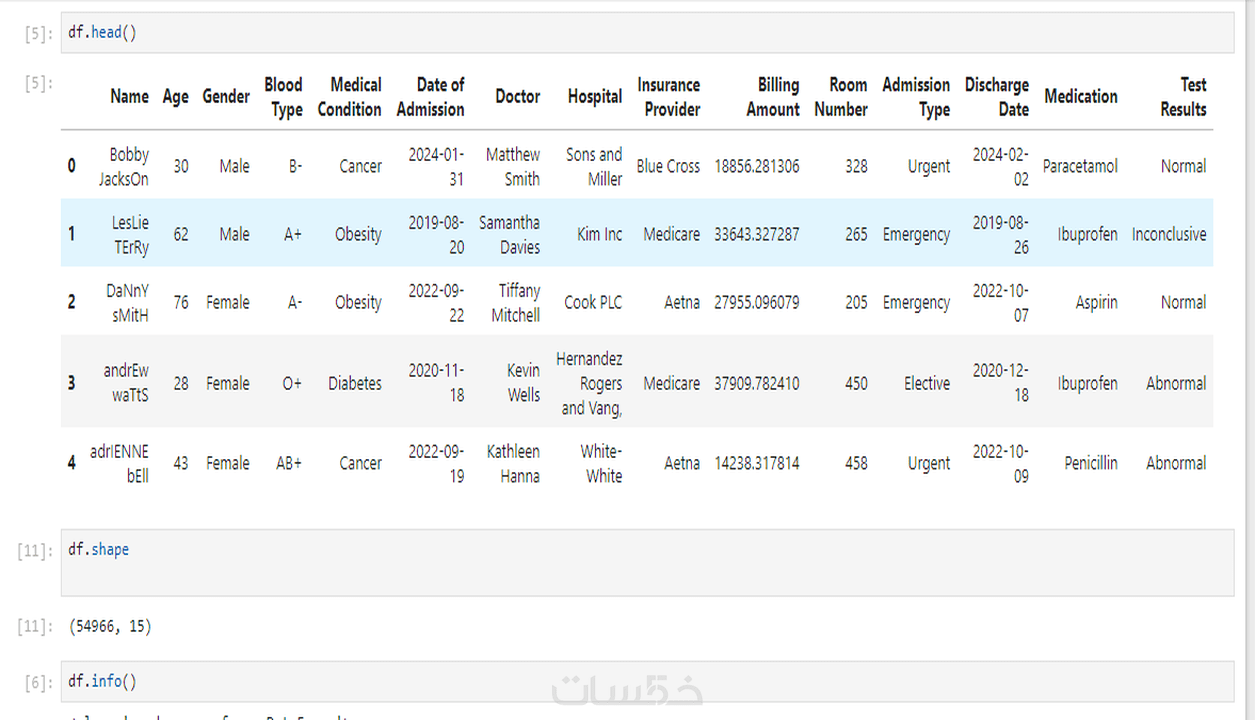
استخدم df.head() وdf.info() وdf.describe() لاستعراض البيانات وفهم بنية الأعمدة وأنواعها وأشكال القيم الموجودة.
فهم المتغيرات:
تحديد المتغيرات الرئيسية، مثل العمر، الجنس، الحالة الصحية، تاريخ الدخول، الأطباء، مزود التأمين، التكلفة، وغيرها من الأعمدة.
2. تنظيف البيانات:
التعامل مع القيم المفقودة:
استخدم طرقًا مثل حذف الصفوف التي تحتوي على العديد من القيم المفقودة أو تعويض القيم المفقودة بمتوسط أو قيمة شائعة (df.fillna() أو df.dropna()).
التعامل مع القيم الشاذة (Outliers):
استخدم الرسوم البيانية مثل boxplot لاكتشاف القيم الشاذة التي قد تؤثر على التحليل.
التعامل مع القيم المكررة:
استخدم df.duplicated().sum() لاكتشاف القيم المكررة في البيانات، وقم بإزالتها باستخدام df.drop_duplicates().
3. استكشاف البيانات (Exploratory Data Analysis - EDA):
يشترط ارسال البيانات و الا يتجاوز حجم البيانات 10 KB و عدد الاعمدة لا يتجاوز 10 اعمدة و عدد الصفوف عن 10 الاف صف .

كلمات مفتاحية
خدمات قد تنال إعجابك











شراء الخدمة
سعر الخدمة
$10.00
تطويرات اختيارية
استخدام النماذج التنبؤية : إذا كنت ترغب في بناء نموذج للتنبؤ بنتيجة اكبر من 85%
20.00
|
|
زيادة 10 اعمدة اضافية
5.00
|


شراء الخدمة
سعر الخدمة
$10.00
تطويرات اختيارية
استخدام النماذج التنبؤية : إذا كنت ترغب في بناء نموذج للتنبؤ بنتيجة اكبر من 85%
20.00
|
|
زيادة 10 اعمدة اضافية
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
