تحليل ومعالجة النصوص العربية والإنجليزية باستخدام تقنيات NLP
تحليل ومعالجة النصوص العربية والإنجليزية باستخدام تقنيات NLP
وصف الخدمة
هل تمتلك نصوصاً ضخمة وتريد استخراج رؤى ذكية منها؟
أقدم لك خدمة احترافية في معالجة اللغات الطبيعية (NLP) باستخدام بايثون لتحويل النصوص الخام إلى نماذج برمجية وتقارير تحليلية دقيقة
تساعدك في تطوير عملك.
حجم البيانات:
تنظيف وEDA: حتى 50,000 سطر.
التعلم العميق: 1,000 - 5,000 سطر لضمان جودة التدريب.
ما سأقوم به في هذه الخدمة:
معالجة النصوص (Preprocessing): تنظيف النصوص (عربي/إنجليزي)، Lemmatizationg ،Tokenization.
التحليل الاستكشافي (EDA): تحليل N-grams، سحابة الكلمات، وتوزيع الأطوال.
تمثيل البيانات (Embedding): تحويل النصوص لأرقام عبر TF-IDF وWord Embeddings.
بناء النماذج: تحليل المشاعر (Sentiment Analysis) وتصنيف النصوص التلقائي.
مميزات الخدمة
تنظيف وتجهيز البيانات Preprocessing
التعامل مع البيانات المفقودة، القيم الشاذة، وتحويل البيانات النصية إلى رقمية
التحليل الاستكشافي EDA
فهم العلاقات بين المتغيرات وتوضيحها من خلال رسوم بيانية احترافية
تمثيل النصوص المتقدم (Word Embeddings)
استخدام تقنيات حديثة مثل (Word2Vec, GloVe, fastText) لضمان فهم العلاقات الدلالية العميقة بين الكلمات بدلاً من مجرد العد التقليدي.
النماذج التسلسلية المتقدمة (Sequence Modeling)
بناء وتطوير نماذج تعتمد على الشبكات العصبية المتكررة (RNN) وخلايا الذاكرة طويلة قصيرة المدى (LSTM) للتعامل مع تدفق النصوص وسياقها
الزمني
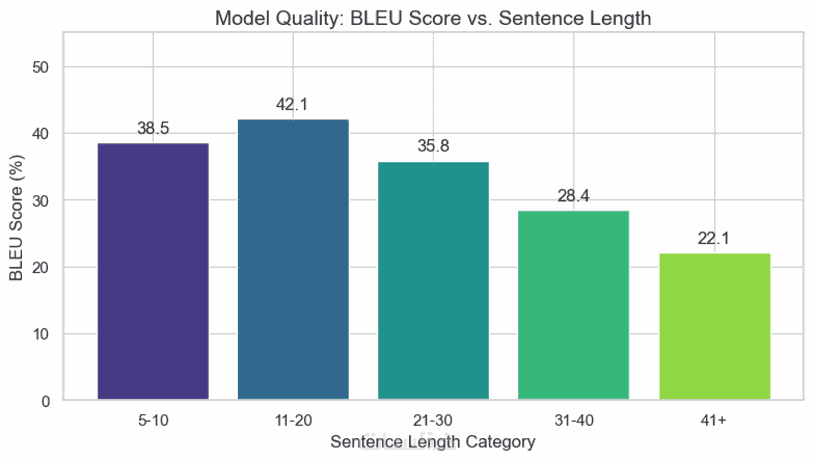
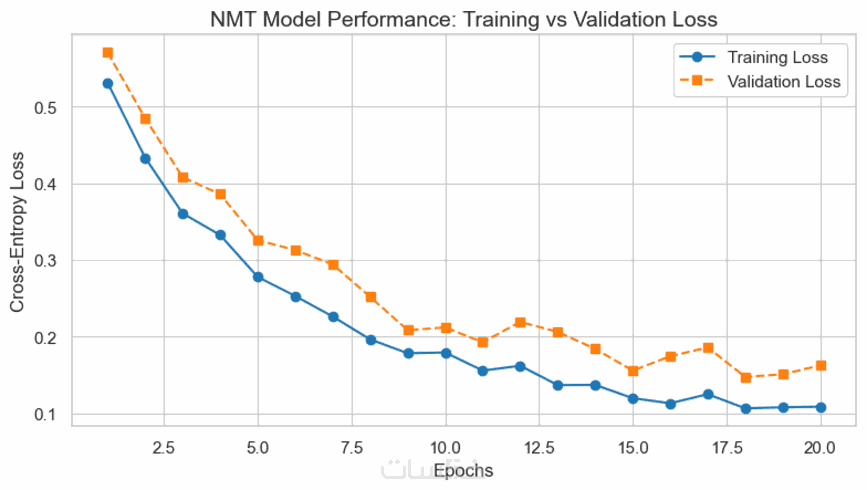

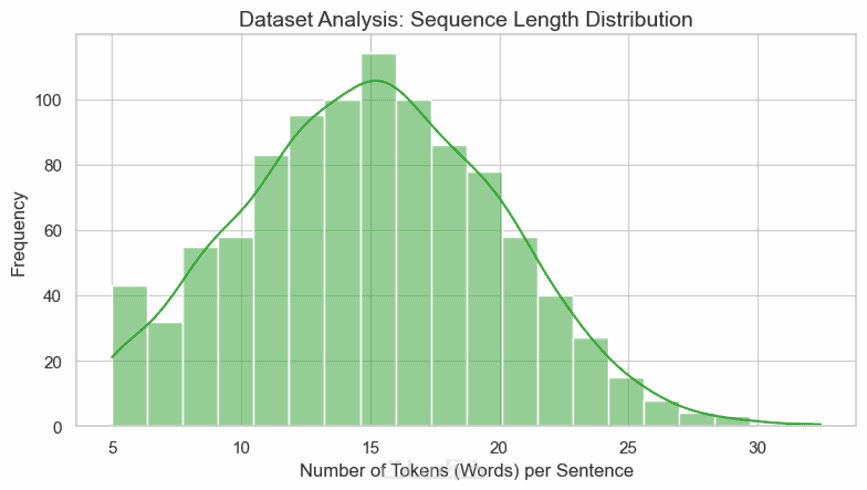
ما الذي ستستلمه
ملف الكود بإستخدام Jupyter Notebook
الكود المصدري كامل ومنظم مع شرح لكل خطوة تمت في المشروع
تقرير النتائج
ملف يوضح النتائج النهائية التي تم الوصول إليها وأداء النموذج
البيانات النهائية
ملف البيانات (Dataset) بعد عمليات التنظيف والمعالجة (حسب الطلب).
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$15.00
خدمات قد تنال إعجابك
كلمات مفتاحية

