بناء نماذج تعلم آلة Machine Learning تنبؤية بدقة عالية
بناء نماذج تعلم آلة Machine Learning تنبؤية بدقة عالية
وصف الخدمة
عنوان الخدمة: بناء وتطوير نماذج تعلم آلة (Machine Learning) احترافية لدعم اتخاذ القرار.
هل تبحث عن تحويل بياناتك إلى أصول رقمية تتنبأ بالمستقبل؟ بصفتي مهندس ذكاء اصطناعي، أقدم لك بناء نماذج تعلم آلة متطورة (Single Task) تعتمد على أدق الخوارزميات البرمجية لحل مشكلات التنبؤ، التصنيف، أو تحليل المخاطر.
ما الذي ستحصل عليه مقابل الخدمة الأساسية:
لضمان الجودة الهندسية، تغطي الخدمة الأساسية "مرحلة التجهيز الفني وبناء الهيكل"، وتشمل:
هندسة الميزات (Feature Engineering): تحويل المتغيرات لرفع كفاءة النموذج (Scaling & Encoding).
اختيار الخوارزمية: تحديد واختيار أنسب خوارزمية (مثل XGBoost أو Random Forest) بناءً على طبيعة بياناتك.
حجم البيانات: التعامل مع ملفات تصل إلى 100,000 صف.
ملاحظة: هذه الخدمة تفترض جاهزية البيانات (نظيفة ومحللة إحصائياً)، وإلا ستحتاج لاختيار التطويرات المناسبة.
مميزات الخدمة
منهجية MLOps الاحترافية:
أبني Pipeline متكامل يضمن استقرار النموذج وسهولة دمجه في بيئة العمل.
التحليل الاستكشافي المعمق (Comprehensive EDA):
أقوم بتشريح البيانات إحصائياً وبصرياً قبل كتابة كود النموذج، لفهم التوزيعات، كشف الأنماط، وتحديد العلاقات بين المتغيرات بدقة علمية.
هندسة الميزات (Advanced Feature Engineering):
أمتلك القدرة على استخراج "القيمة المخفية" من بياناتك لرفع دقة التوقعات لأقصى حد ممكن.
الاستقرار والموثوقية:
أعتمد تقنيات الـ Validation الصارمة لضمان أن النموذج يعمل بدقة على البيانات الجديدة (Unseen Data) وتجنب مشاكل الـ Overfitting.
الأداء العالي:
خبرة واسعة في تطويع أقوى الخوارزميات (XGBoost, Random Forest, LightGBM) لتحقيق أفضل النتائج بأقل استهلاك للموارد.
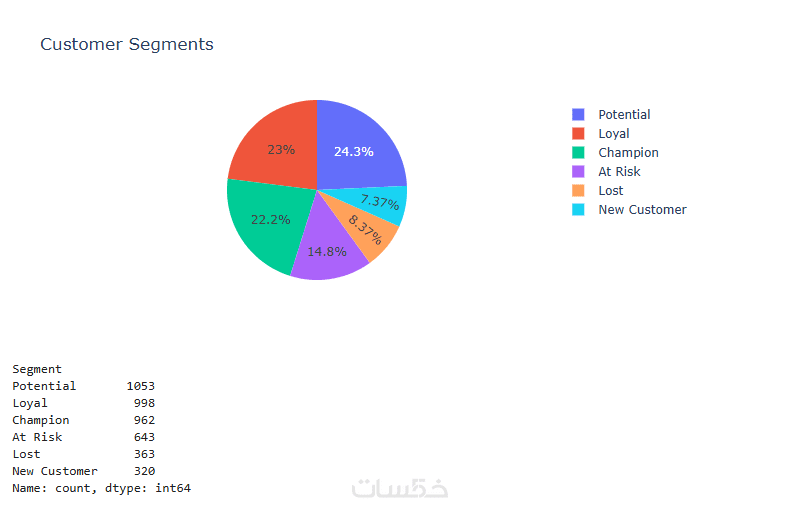
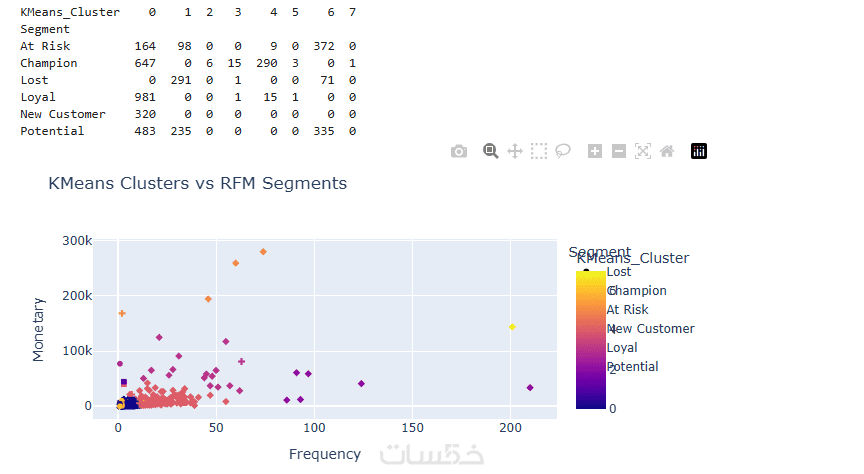
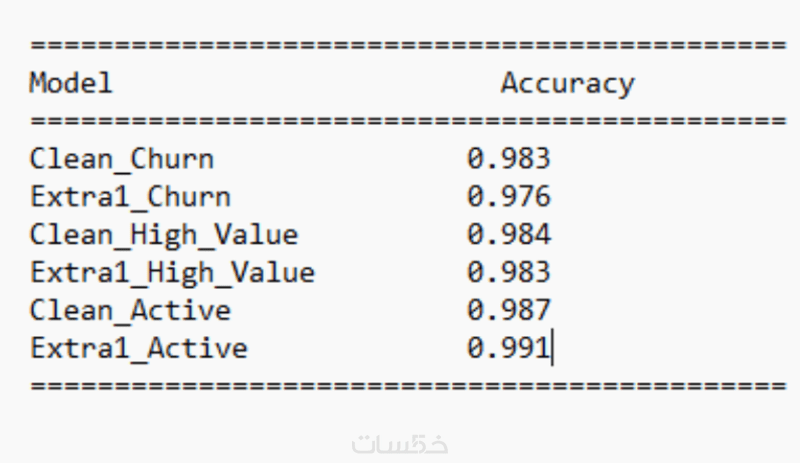
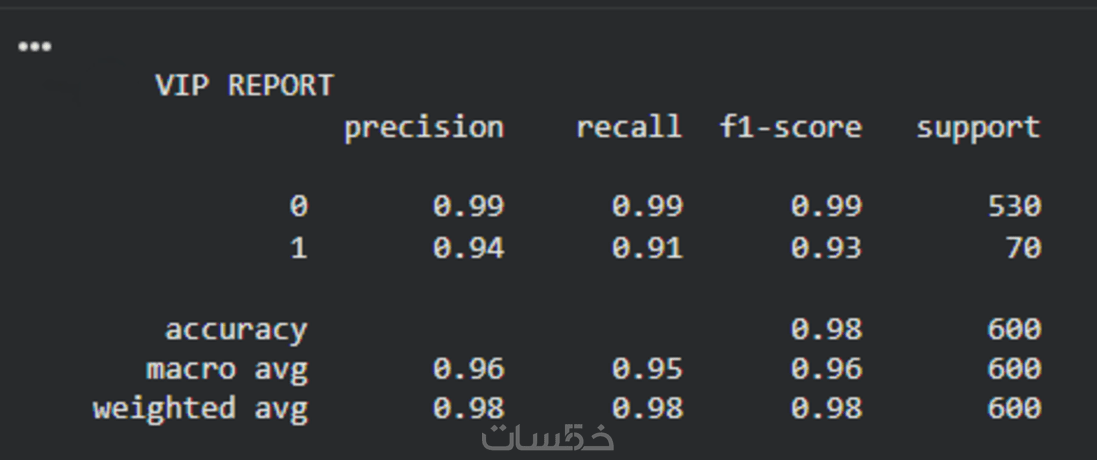
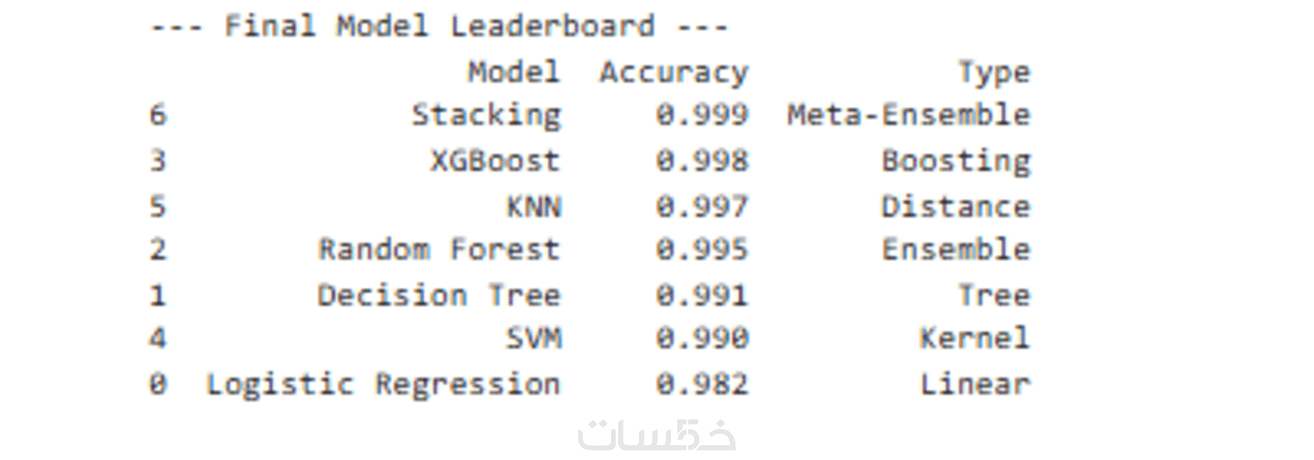
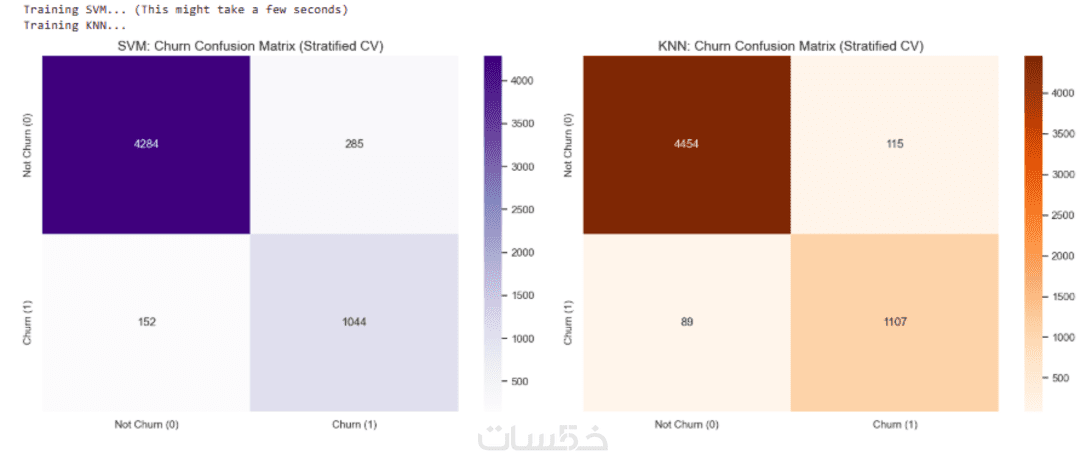
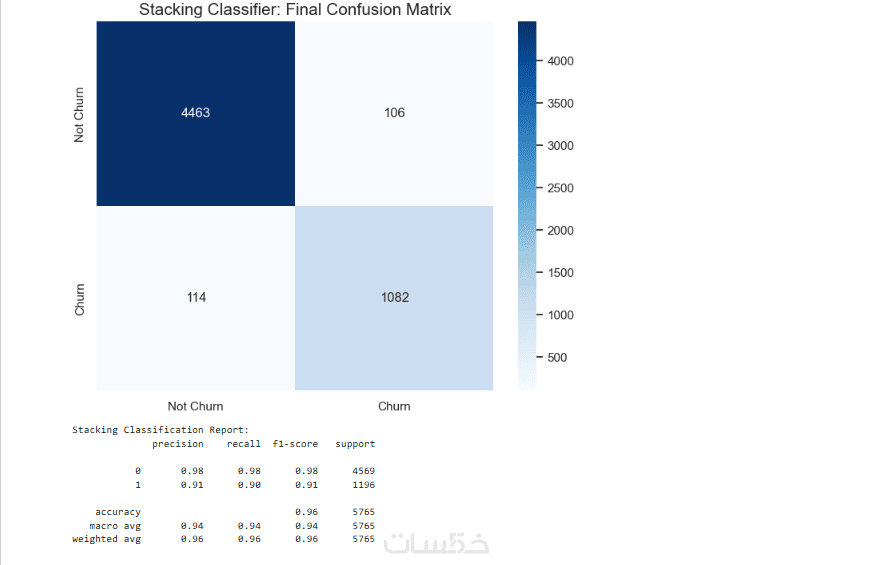
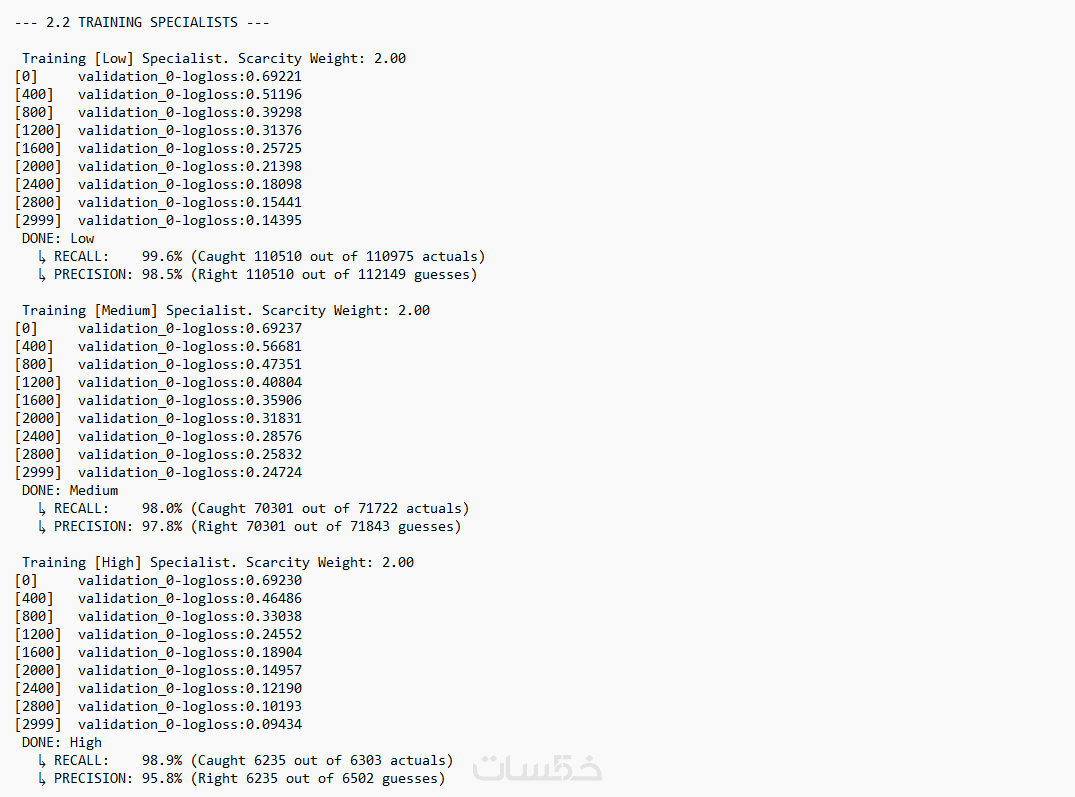
ما الذي ستستلمه
ملف النموذج المدرب (Trained Model File):
نسخة جاهزة للتشغيل بصيغة تقنية احترافية (مثل .pkl أو .h5).
وثيقة أداء النموذج (Performance Report):
تقرير PDF يتضمن كافة مقاييس النجاح (Accuracy, F1-Score, Precision) والرسوم البيانية التوضيحية لنتائج الاختبار.
دليل التشغيل:
شرح مبسط ومكتوب لكيفية استدعاء النموذج وتمرير البيانات إليه للحصول على التوقعات.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$15.00
تطويرات اختيارية
معالجة بيانات ضخمة (حتى 500,000 صف)
20.00
|
|
معالجة و تجهيز البيانات الخام (Data Preprocessing and Cleaning)
10.00
|
|
بناء واجهة تشغيل تفاعلية (Web Interface: Streamlit, Power BI)
30.00
|


شراء الخدمة
سعر الخدمة
$15.00
تطويرات اختيارية
معالجة بيانات ضخمة (حتى 500,000 صف)
20.00
|
|
معالجة و تجهيز البيانات الخام (Data Preprocessing and Cleaning)
10.00
|
|
بناء واجهة تشغيل تفاعلية (Web Interface: Streamlit, Power BI)
30.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
