بناء نموذج تنبؤي احترافي باستخدام الانحدار وتحليل البيانات
بناء نموذج تنبؤي احترافي باستخدام الانحدار وتحليل البيانات
وصف الخدمة
المهمة 1: تحويل البيانات الخام من ملفات Excel أو CSV إلى لوحات بيانات تفاعلية تدعم اتخاذ القرار.
المهمة 2: تصميم واجهة تعمل على الكمبيوتر والموبايل بشكل متوافق (responsive).
المهمة 3: عرض مؤشرات الأداء الرئيسية (KPIs) بشكل مباشر مع إمكانية التصفية والبحث.
المهمة 4: تحديث البيانات يدويًا عند رفع ملف جديد أو تلقائيًا حسب مصدر البيانات (حسب الطلب).
المهمة 5: التعامل مع البيانات ضمن حدود حتى 1,000,000 صف و500 عمود وحجم إجمالي حتى 500MB، مع دعم صيغ CSV، Excel (.xlsx)، أو JSON، على أن يحدد العميل الأعمدة المستخدمة كمؤشرات (KPIs) والأعمدة المخصصة للتصفية (مثل التاريخ، المنطقة، الفئة).
المهمة 6: تنفيذ تنظيف أساسي للبيانات يشمل حذف التكرار ومعالجة القيم الناقصة وتوحيد التنسيقات.
المهمة 7: تسليم لوحة بيانات جاهزة للاستخدام مع شرح طريقة التشغيل والتحديث.
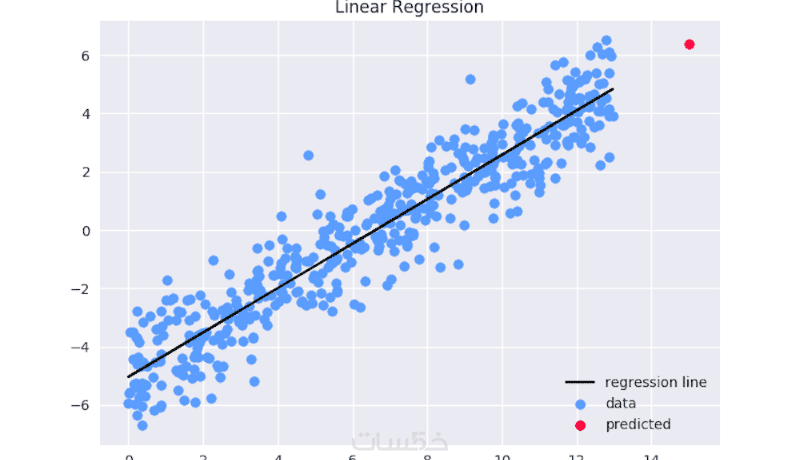
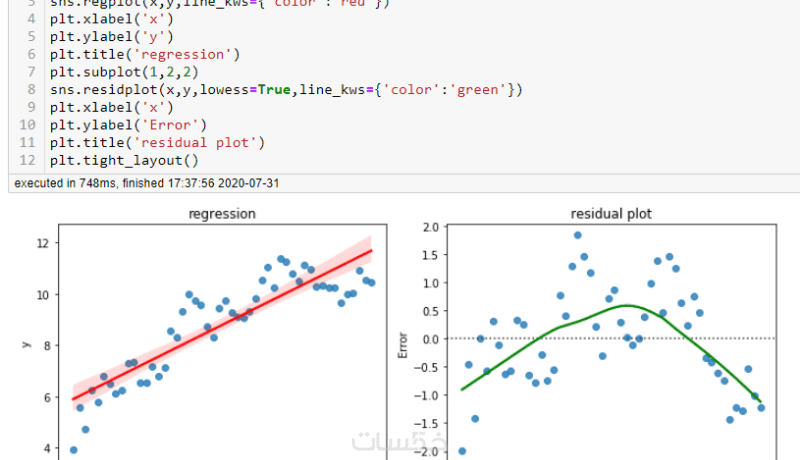
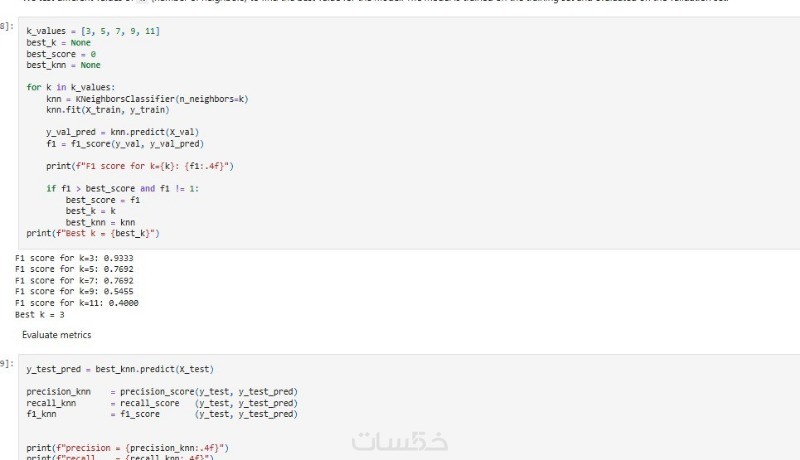
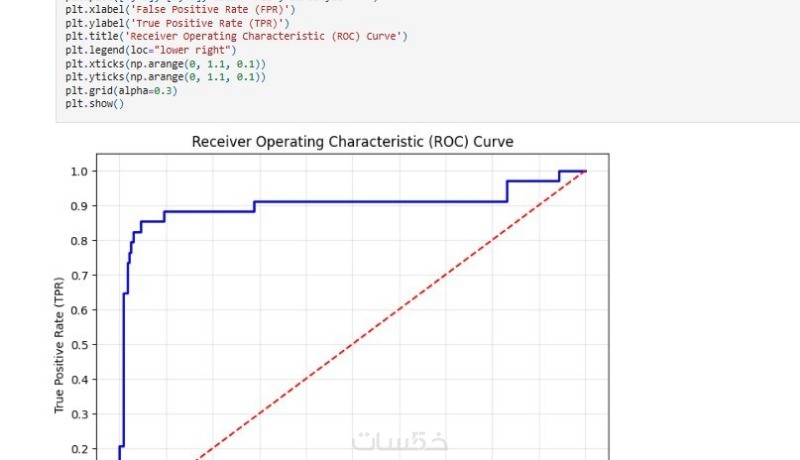
مميزات الخدمة
تطبيق احترافي لمنهجية IBM:
لن أكتفي بكتابة الكود فقط، بل سأتبع مراحل منهجية علم البيانات بدءاً من فهم المشكلة
معالجة متقدمة للبيانات:
التعامل مع القيم المفقودة، تطبيع البيانات (Normalization)، وتحويل المتغيرات الفئوية إلى رقمية باستخدام Numpy, Pandas
اختيار النموذج الأمثل:
مقارنة بين عدة خوارزميات انحدار من مكتبة (Scikit-Learn (Linear Regression, Ridge, Polynomial. واختيار الأفضل بناءً على مقاييس تقييم دقيقة (R² Score, MSE, MAE).
تحليل إحصائي استكشافي:
ستحصل على تحليل للارتباطات (Correlation) بين المتغيرات لفهم العوامل الأكثر تأثيراً في نتائجك
شفافية كاملة:
تسليم كود بايثون واضح ومنظم (Jupyter Notebook) يسمح لك بتعديله أو إعادة تشغيله بنفسك مستقبلاً.
ما الذي ستستلمه
تقرير تحليل النتائج (PDF):
شرح مبسط للنتائج يتضمن دقة النموذج النهائي، والرسوم البيانية للعلاقة بين القيم الحق
كود بايثون تفاعلي (Jupyter Notebook):
الملف الكامل الذي يحتوي على جميع مراحل العمل (استيراد البيانات، التنظيف، بناء النموذج, الاختبار)
النموذج المُدرّب (ملف .pkl أو .joblib):
يمكنك استخدامه فوراً للتنبؤ بأي بيانات جديدة دون الحاجة لإعادة تدريبه.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تحليل إحصائي استكشافي كامل (Correlation matrix, heatmaps, outliers)
5.00
|
|
تسليم كود بايثون واضح ومنظم (Jupyter Notebook) يسمح لك بتعديله أو إعادة تشغيله بنفسك مستقبلا
5.00
|


شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تحليل إحصائي استكشافي كامل (Correlation matrix, heatmaps, outliers)
5.00
|
|
تسليم كود بايثون واضح ومنظم (Jupyter Notebook) يسمح لك بتعديله أو إعادة تشغيله بنفسك مستقبلا
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
