تحليل بيانات وبناء مودل تعلم الالة للتوقع Machine learning
تحليل بيانات وبناء مودل تعلم الالة للتوقع Machine learning
وصف الخدمة:
أهلاً بك! معاك محمد أشرف، مهندس ذكاء اصطناعي متخصص في علوم البيانات Data Science.
كيف سأساعدك في هذا المشروع؟
إذا كان لديك ملف بيانات (Excel, CSV) يصل حجمه الى مليون سجل،عدد أعمدة Features لا يتجاوز 30
فيمكنني تقديم الآتي باحترافية:
تهيئة وتنظيف البيانات (Data Cleaning): معالجة القيم المفقودة والمكررة لضمان أن تحليلنا مبني على أساس دقيق 100%.
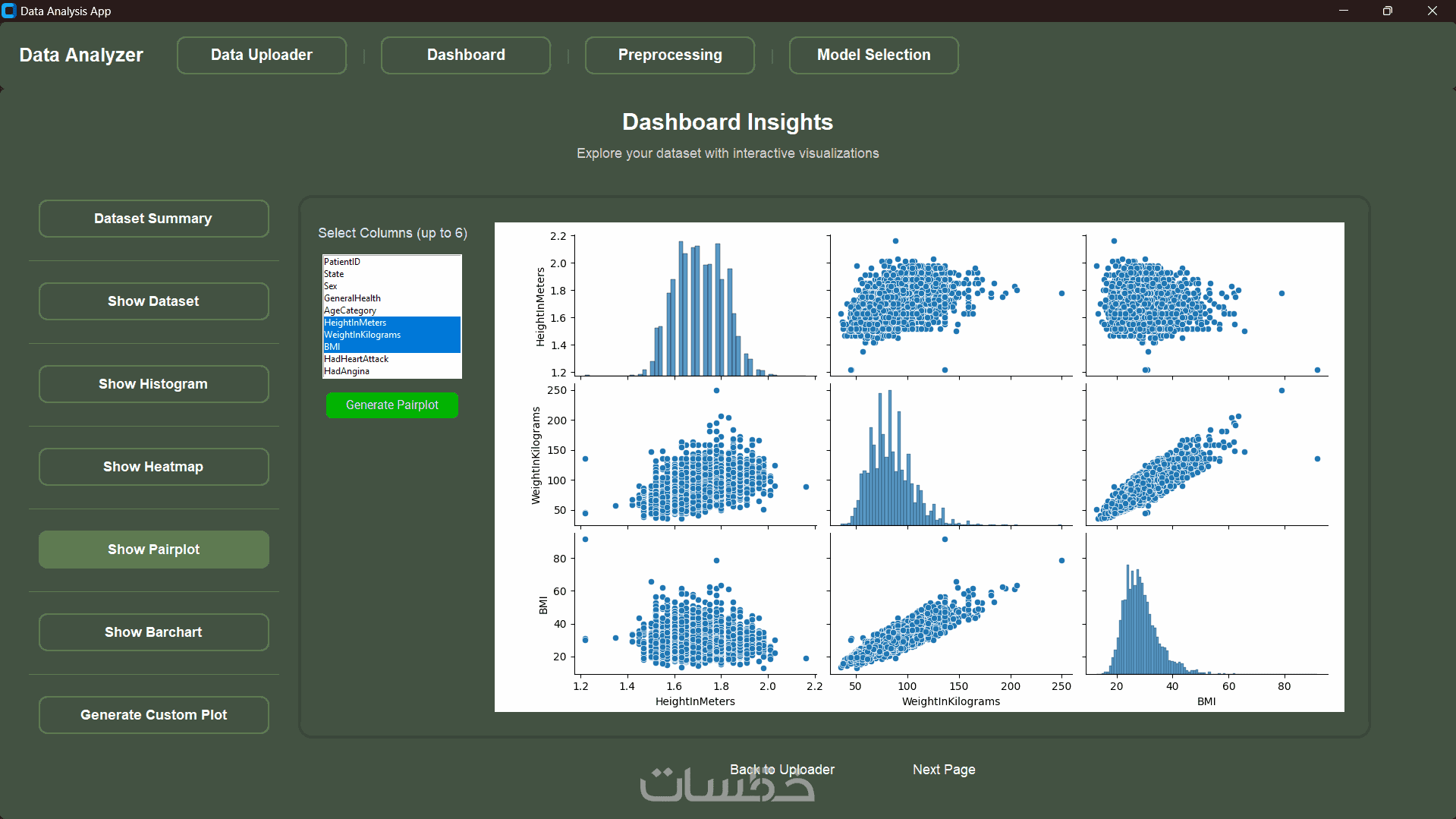
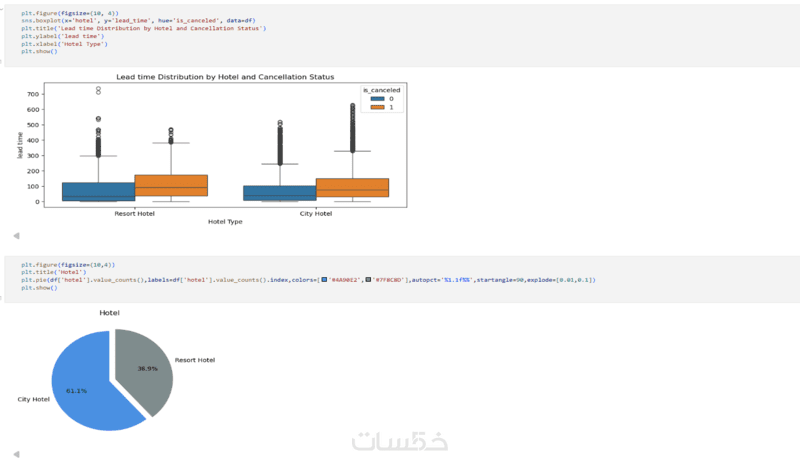
التحليل الاستكشافي (EDA): استخراج الأنماط المخفية، ورسم البيانات بوضوح للإجابة عن أسئلة مشروعك المعقدة.
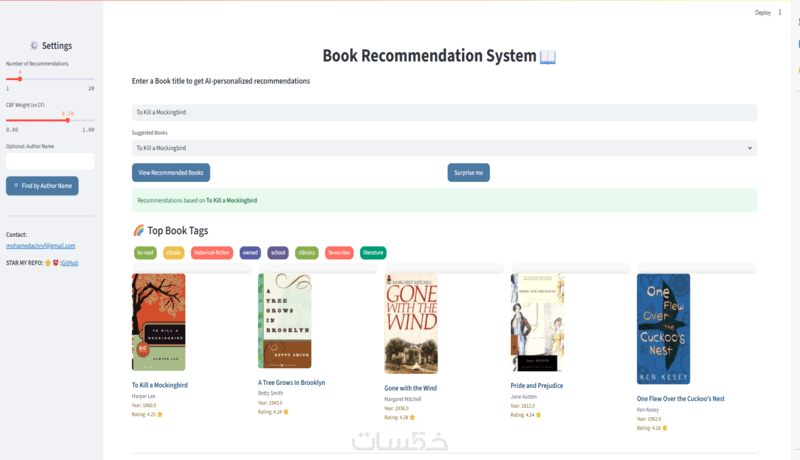
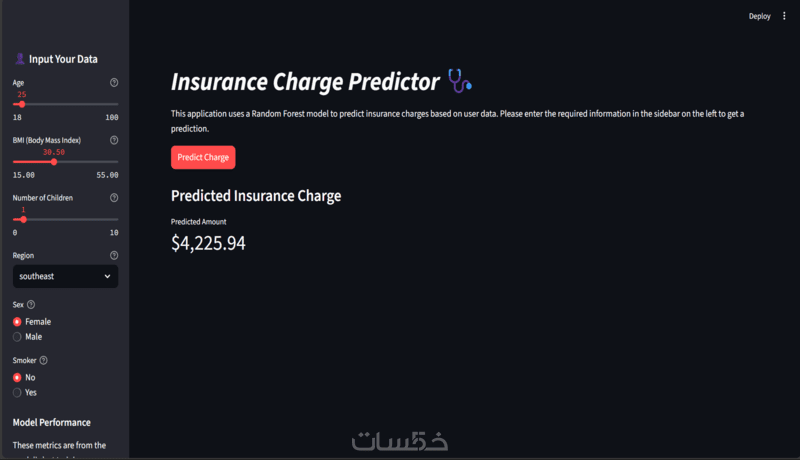
بناء نماذج التنبؤ (Regression): تصميم خوارزميات تتوقع الأرقام المستقبلية (مثل: التنبؤ بحجم المبيعات، أو أسعار العقارات).
بناء نماذج التصنيف (Classification): تقسيم البيانات بذكاء (مثل: تصنيف سلوك العملاء، أو تحديد المعاملات غير العادية).
الأدوات التي أعتمد عليها (Python):
Pandas & NumPy (للهندسة ومعالجة البيانات)
Scikit-learn & TensorFlow (لبناء وتدريب النماذج)
Matplotlib & Seaborn (لرسم البيانات واستخراج الرؤى)
تواصل معي الان لخدمة سريعة وجودة عالية
مميزات الخدمة
المميزات
تنظيف ومعالجة البيانات (Data Cleaning) باحترافية للتعامل مع القيم المفقودة والمكررة.
تحسين أداء النماذج (Hyperparameter Tuning) للوصول إلى أعلى دقة ممكنة.
تواصل مستمر وسرعة في التسليم
ما الذي ستستلمه
ما الذي ستستلمه عند انتهاء الخدمة؟
النموذج النهائي (Model) جاهز للاستخدام الفوري.
الكود البرمجي كاملاً ومنظماً (Clean Code) بصيغة Jupyter Notebook، مع تعليقات توضيحية لكل خطوة.
تقرير احترافي ومبسط يشرح لك رحلة البيانات من البداية: كيف نظفناها، وسبب اختيارنا للنموذج النهائي، لتكون على دراية تامة بكل تفصيلة.
حجم العمل المقدم في الخدمة الأساسية:
حجم العمل المقدم
معالجة وتنظيف ملف بيانات واحد يصل حجمه إلى مليون سجل كحد أقصى.
عدد الأعمدة (Features) لا يتجاوز 30 عموداً.
تنفيذ تحليل استكشافي شامل (EDA) مع الرسوم البيانية الأساسية.
بناء نموذج واحد للتنبؤ أو التصنيف وفقاً لاحتياجات المشروع.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
واجهة رسومية تفاعلية باستخدام streamlit
5.00
|
|
بناء موديل تعلم عميق مناسب Deep Learning
5.00
|


شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
واجهة رسومية تفاعلية باستخدام streamlit
5.00
|
|
بناء موديل تعلم عميق مناسب Deep Learning
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
