تصنيف وتحليل البيانات النصية باستخدام خوارزميات تعلم الآلة
تصنيف وتحليل البيانات النصية باستخدام خوارزميات تعلم الآلة
وصف الخدمة
هل تمتلك بيانات نصية (تغريدات، مراجعات عملاء، مقالات، أو رسائل) وترغب في تحليلها أو تصنيفها آلياً بدقة عالية؟
أقدم لك خدمة احترافية لبناء وتطوير نماذج معالجة اللغات الطبيعية (NLP) باستخدام لغة بايثون. سأقوم بتحويل نصوصك الخام إلى نماذج ذكاء اصطناعي قادرة على الفهم والتصنيف لاستخراج رؤى قيمة من بياناتك.
ما ستحصل عليه في هذه الخدمة:
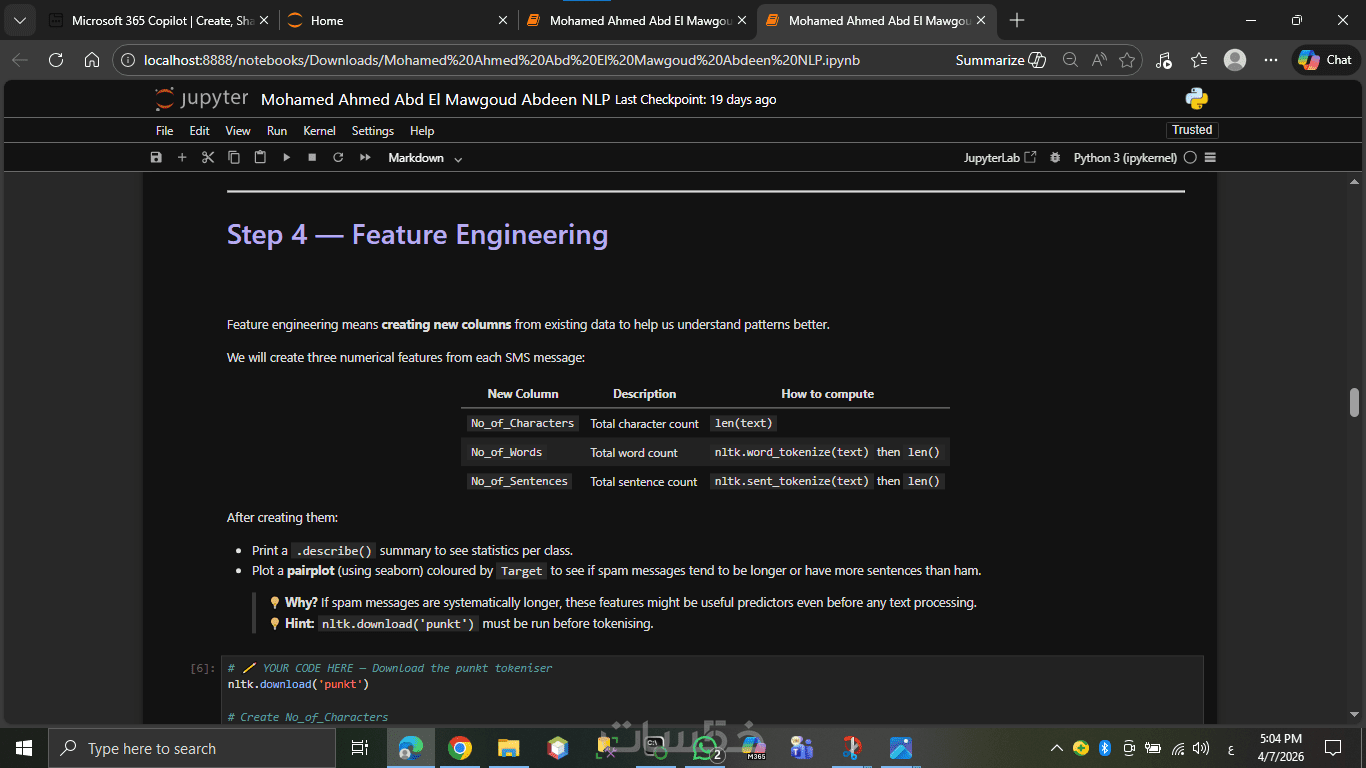
تنظيف ومعالجة البيانات النصية (Text Preprocessing) واستخراج الميزات (مثل TF-IDF).
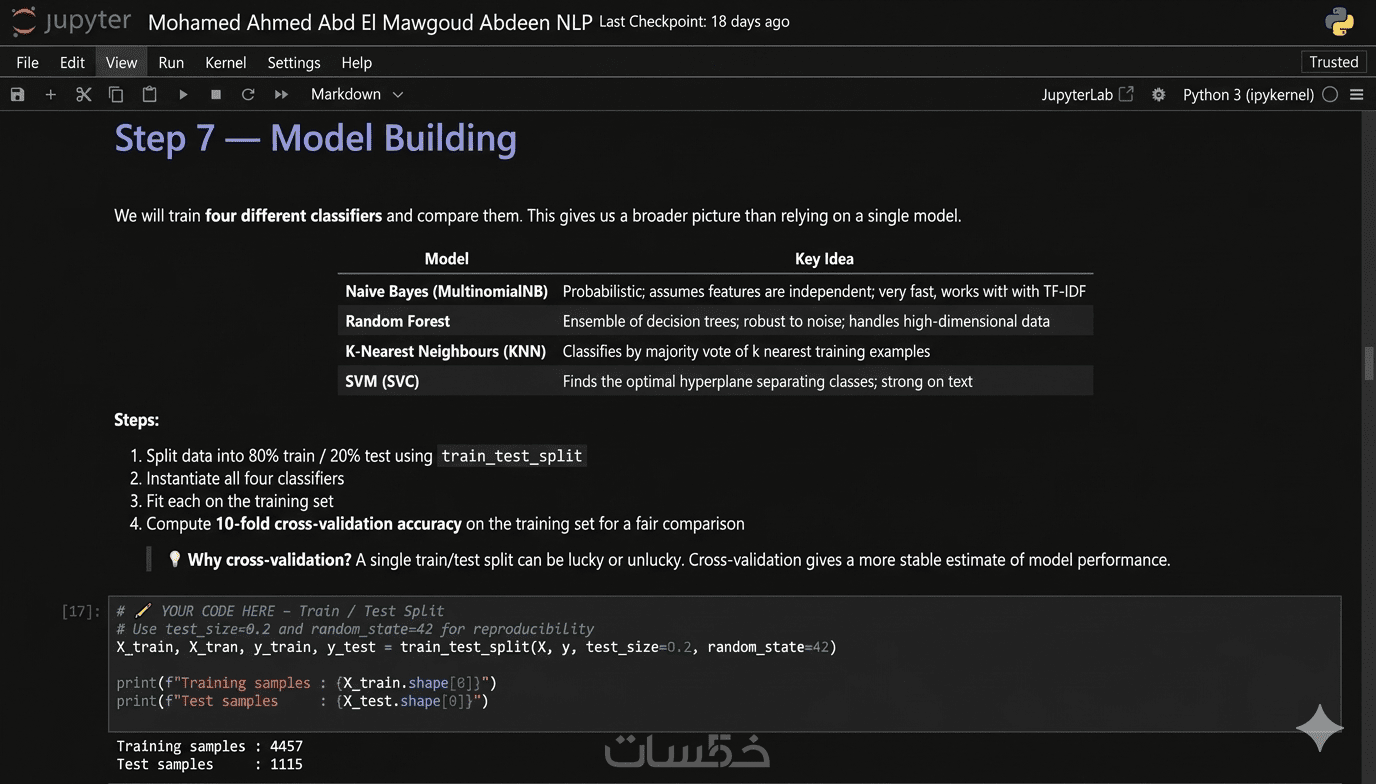
تدريب ومقارنة عدة خوارزميات تعلم آلة (مثل: SVM, Random Forest, Naive Bayes, KNN) لاختيار النموذج الأمثل لبياناتك.
استخدام تقنيات التقييم المتقدمة (10-fold Cross-Validation) لضمان استقرار وقوة النموذج.
تسليم ملف (Jupyter Notebook / Google Colab) منظم، منسق، وموثق بشرح تفصيلي لكل خطوة برمجية.
تعليمات للمشتري.
لكي نبدأ العمل بأفضل شكل، أرجو توفير الآتي:
شرح واضح للهدف من النموذج (مثال: تحليل المشاعر Sentiment Analysis، تصنيف الأخبار، اكتشاف البريد المزعج، إلخ).
إرفاق ملف البيانات النصية (Dataset) المراد العمل عليه (يفضل بصيغة CSV أو Excel).
توضيح لغة البيانات النصية .
برجاء مراسلتي قبل طلب الخدمة لمناقشة تفاصيل المشروع وحجم البيانات لضمان الوصول لأفضل نتيجة ممكنة.
حجم العمل مقابل الخدمة الأساسية
تطبيق خطوات المعالجة والتنظيف الأساسية (إزالة الرموز، الأرقام، وعلامات الترقيم) وتحويل النصوص باستخدام (TF-IDF).
العمل على مجموعة بيانات نصية (Dataset) صغيرة الحجم (بحد أقصى 1000 صف/نص).
تدريب النماذج الأساسية المذكورة لاستخراج مقاييس الأداء الأولية (مثل Accuracy و F1-Score).
تسليم الكود البرمجي يعمل بكفاءة.
كلمات مفتاحية
خدمات قد تنال إعجابك













شراء الخدمة
سعر الخدمة
$5.00
خدمات قد تنال إعجابك
كلمات مفتاحية

