تدريب نماذج ذكاء صنعي ونشرها
تدريب نماذج ذكاء صنعي ونشرها
أي نموذج ML & DL
نظامًا للتنبؤ ،كشف الانحرافات، التصنيف، التوصية، الرؤية الحاسوبية أو معالجة اللغة الطبيعية. نعتمد على أحدث تقنيات التعلم الآلي والتعلم العميق لبناء حلول قابلة للتوسع، مدعومة ببياناتك الخاصة أو مصادر عامة بأي لغة، مع التزام مع اخلاقيات المهنة.
-- حالات الاستخدام الشائعة:
- التنبؤ بسلوك العملاء أو الطلبات
- اكتشاف الاحتيال أو الحالات الشاذة
- تصنيف الصور أو النصوص
- أنظمة التوصية الذكية
- تحليل المشاعر والمحادثات
-- الخدمة الأساسية وحجم العمل:
- إعداد البيانات: تنظيف وتحضير مجموعة بيانات تصل إلى 400,000 سجل.
- بناء النموذج: تدريب عدة نماذج (صغيرة أو متوسطة مثل Random Forest, Decision Trees أو SVM, Logistic Regression أو Neural Networks صغيرة أو Autoencoders أساسية) حسب المهمة، مع ضبط المعاملات الأنسب.
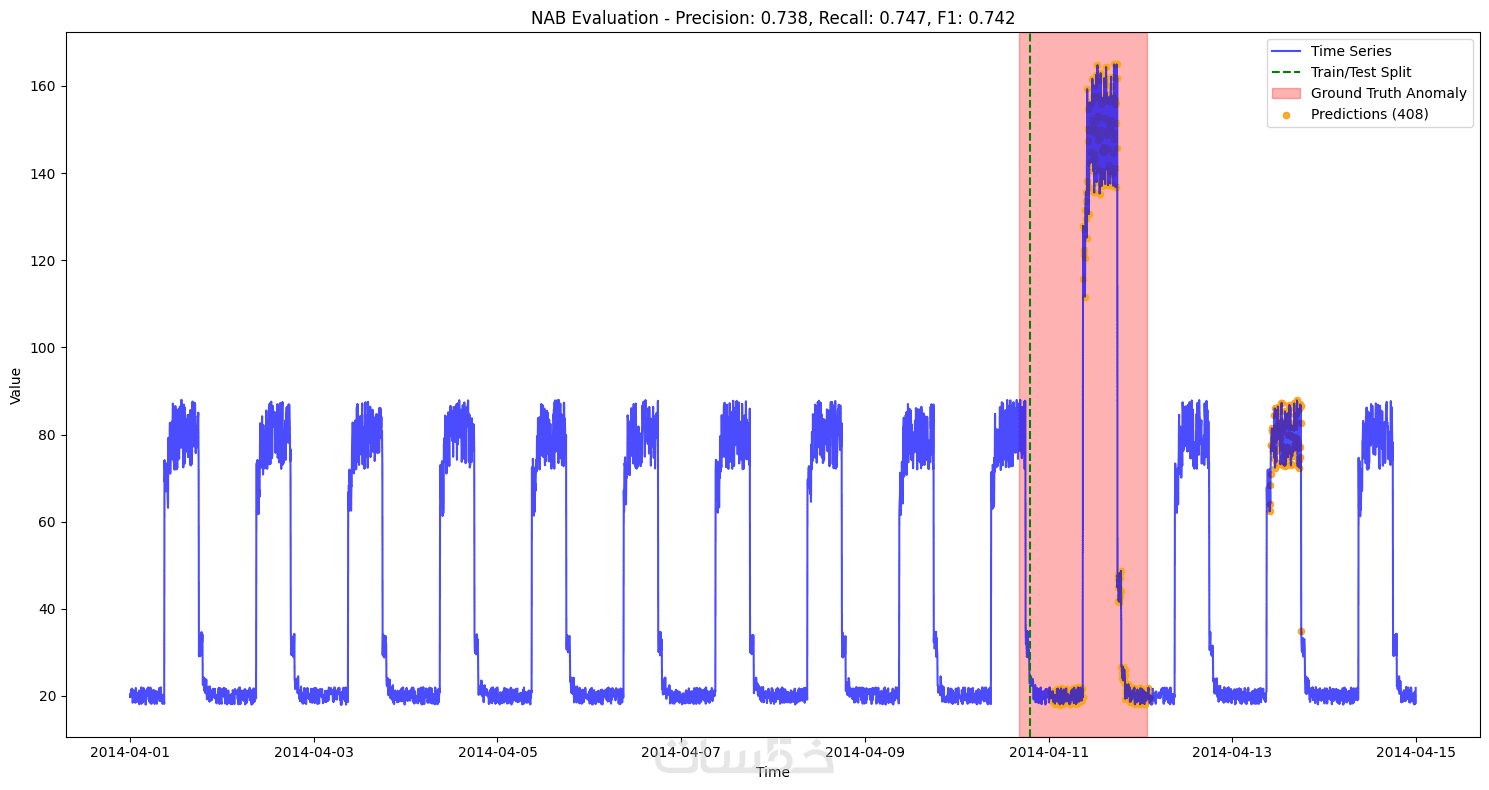
- التدريب والتقييم: تقرير أداء يشمل 3 مقاييس على الأقل (الدقة، الاستدعاء، etc.)
- التوثيق: ملف README يشرح:
آلية تشغيل النموذج
شكل البيانات المدخلة والمخرجات
كيفية استخدام الكود
ما الذي نقدمه؟
تحليل البيانات الأولي
استخراج البيانات من المواقع، تنظيف البيانات، التعامل مع القيم المفقودة، واستخراج الميزات الأكثر تأثيرا وحتى تقليل الابعاد PCA
تصميم النموذج المناسب
اختيار الخوارزمية المثلى (مثل الشبكات العصبية، أشجار القرار، أو نماذج الانحدار) بناءً على نوع المشكلة
تدريب النموذج وتقييمه
استخدام تقنيات التحقق المتقاطع وتحسين الأداء عبر ضبط المعاملات.
نشر النموذج في بيئة الإنتاج
توفير واجهات API أو دمج النموذج في تطبيقاتك الحالية.
التوثيق والدعم الفني
شرح آلية عمل النموذج، مؤشرات الأداء، وكيفية استخدامه بفعالية.
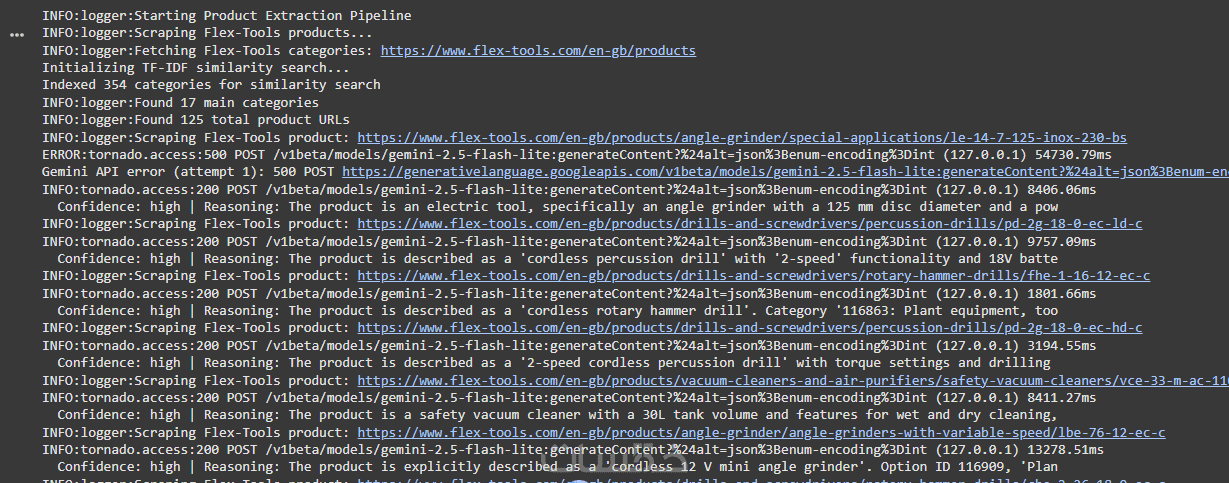
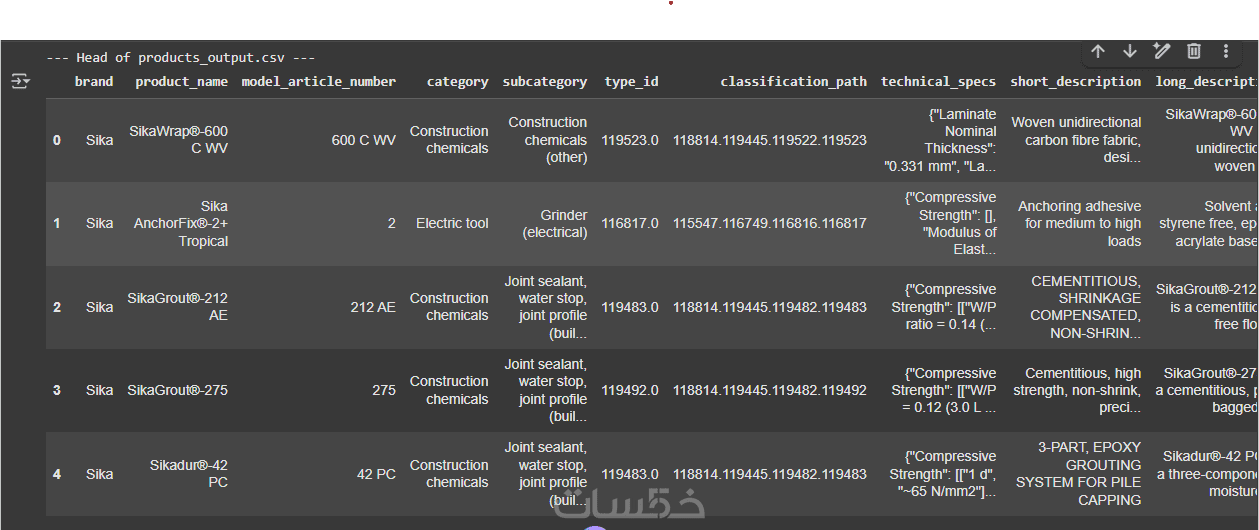
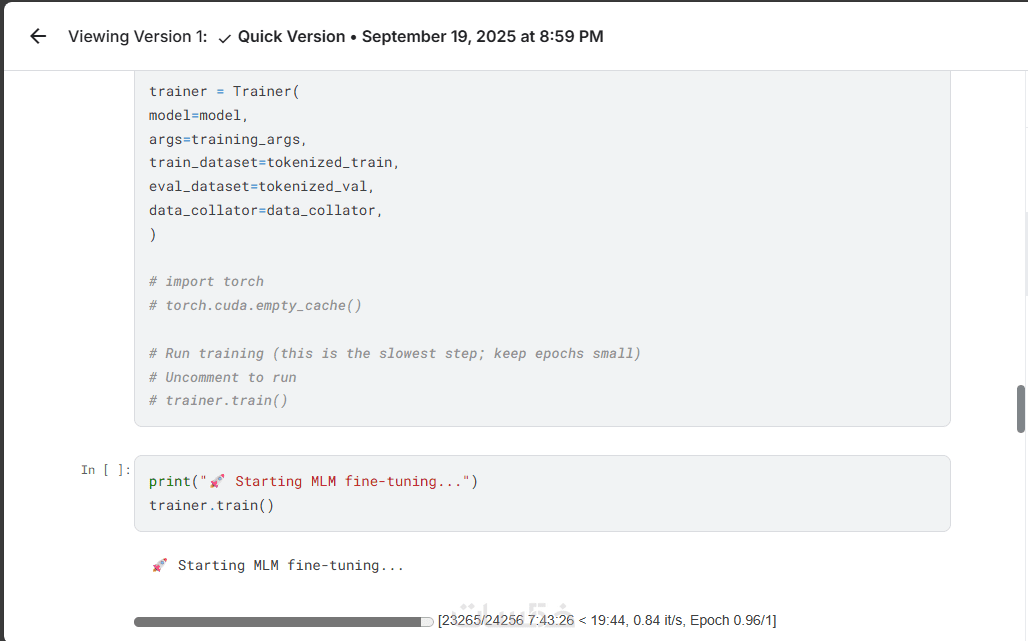
اعادة تدريب نموذج على بيانات خاصة
تدريب عدة نماذج على بيانات credit-g
التنبؤ بالشذوذ عن طريق autoencoders
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$25.00
تطويرات اختيارية
التنقيب عن البيانات من مستندات أو مواقع
10.00
|
|
واجهة وصول على الانترنت
20.00
|
|
تدريب نموذج ضخم LLM أو نماذج الصور او الصوت
40.00
|
|
شرح الكود والنشر عبر meeting
10.00
|
|
تفسير النتائج ومراقبة البيانات الجديدة والنموذج
40.00
|


شراء الخدمة
سعر الخدمة
$25.00
تطويرات اختيارية
التنقيب عن البيانات من مستندات أو مواقع
10.00
|
|
واجهة وصول على الانترنت
20.00
|
|
تدريب نموذج ضخم LLM أو نماذج الصور او الصوت
40.00
|
|
شرح الكود والنشر عبر meeting
10.00
|
|
تفسير النتائج ومراقبة البيانات الجديدة والنموذج
40.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
