استخراج بينانات من مواقع ويب
استخراج بينانات من مواقع ويب
وصف الخدمة
هل تحتاج إلى جمع بيانات محددة من مواقع الويب وتحليلها، ولكن النقل اليدوي يستهلك الكثير من وقتك ومجهودك؟
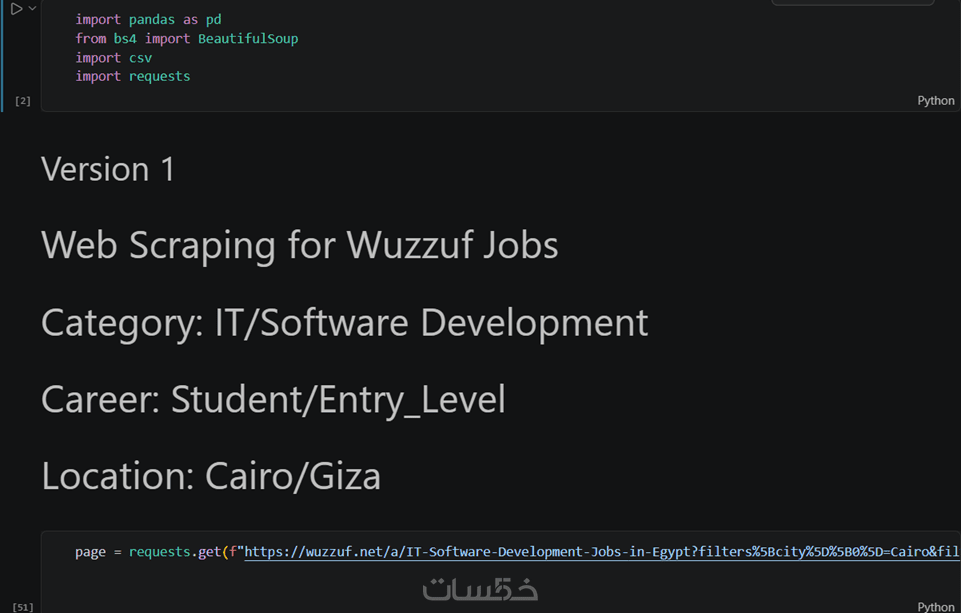
أقدم لك خدمة كشط واستخراج البيانات (Web Scraping) من صفحات الويب المفتوحة بشكل آلي وسريع باستخدام لغة Python والمكتبات الخفيفة والفعالة (BeautifulSoup & Requests).
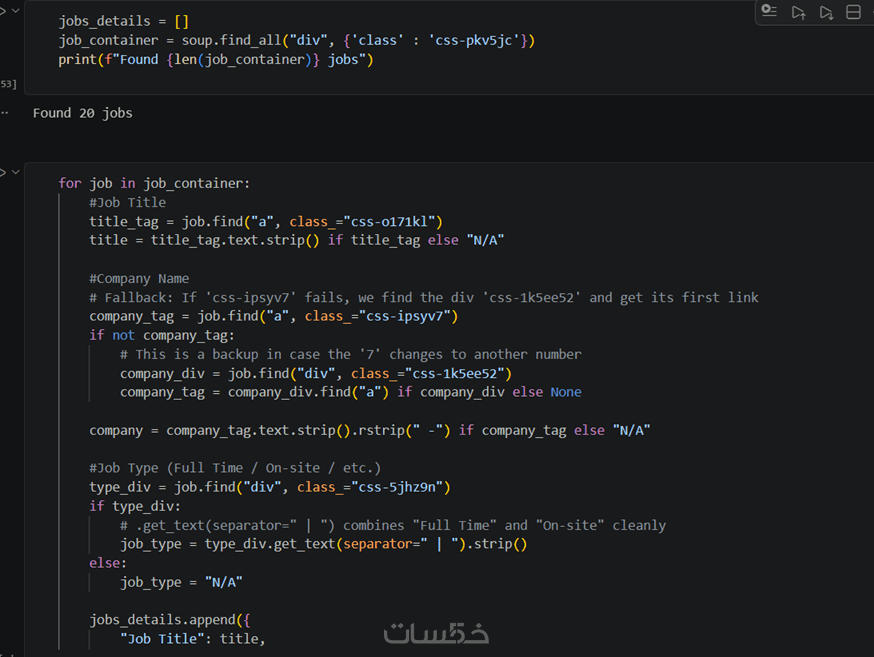
هذه الخدمة مثالية لجمع بيانات المنتجات، دلائل الشركات، تفاصيل الوظائف (مثل المسمى الوظيفي، اسم الشركة، ونوع العمل)، أسعار المنافسين، أو أي معلومات مهيكلة مرئية على صفحات الويب التي لا تتطلب محاكاة معقدة لمتصفحات الجافاسكريبت.
ساعمل علي استخراج لحد اقصي 500 صف و 10 اعمدة لمختلف المواقع
مميزات الخدمة
السرعة الفائقة الكفاءة
أعتمد على تقنيات برمجية خفيفة الوزن لقراءة الكود المصدري مباشرة (بدون الاعتماد على المتصفحات الوهمية البطيئة)، مما يضمن استخراج البيانات في وقت قياسي.
تنظيف وتنسيق البيانات
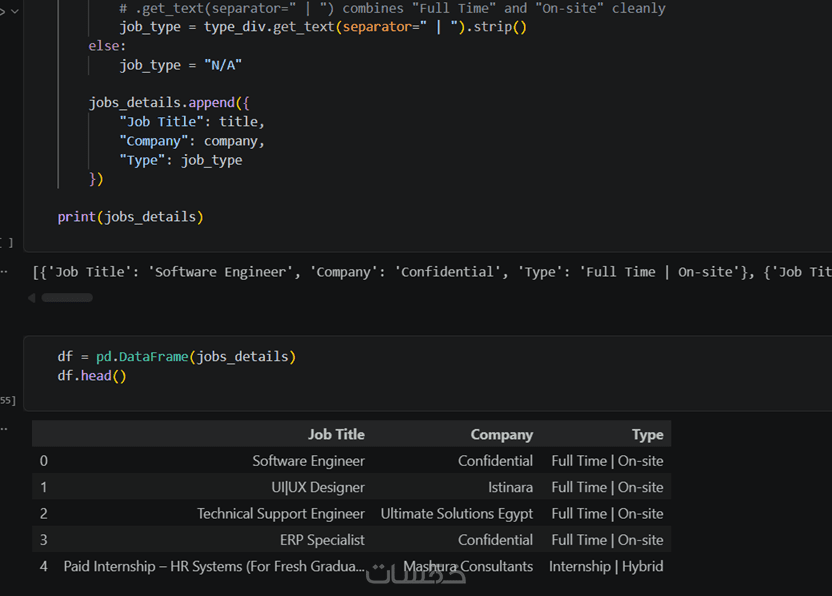
لا أكتفي باستخراج النصوص الخام، بل أقوم بتنظيفها برمجياً وتنظيمها في جداول باستخدام مكتبة pandas لتكون خالية من التشوهات وجاهزة للتحليل.
الدقة العالية
برمجة دقيقة لاستهداف العناصر المطلوبة فقط لضمان دقة البيانات المستخرجة بنسبة 100%.
ما الذي ستستلمه
قابل قيمة الخدمة الأساسية، ستحصل على
ملف بيانات منظم ومرتب بالصيغة التي تفضلها (Excel أو CSV) يحتوي على البيانات المطلوبة.
استخراج البيانات لعدد يصل إلى (مثلاً: 500 إلى 1000 سجل) بناءً على حجم وتوافر البيانات في الموقع.
ميزة إضافية مجانية: إمكانية تسليمك الكود المصدري (ملف Jupyter Notebook .ipynb) الذي تم تطويره خصيصاً لمشروعك لتتمكن من الاطلاع على طريقة العمل
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$5.00
خدمات قد تنال إعجابك
كلمات مفتاحية

