بناء نماذج تعلم آلي Machine Learning للتصنيف والتنبؤ
بناء نماذج تعلم آلي Machine Learning للتصنيف والتنبؤ
وصف الخدمة
الادوات المستخدمة:
1. Pandas و NumPy: لتحضير وتنظيف البيانات.
2. Scikit-learn (Sklearn): لبناء نماذج الانحدار (Regression) والتصنيف (Classification).
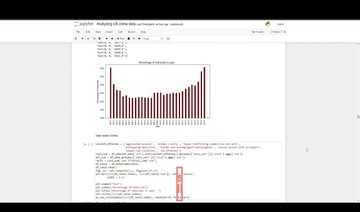
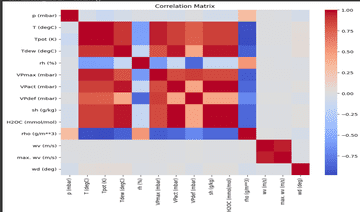
3. Matplotlib و Seaborn: لتوضيح النتائج عبر الرسوم البيانية.
4. Jupyter Notebook: لعرض الكود والتحليل بشكل منظم وسهل الفهم.
تشمل الخدمة الأساسية:
1. تحليل بيانات تصل إلى 10000 صف.
2. إنشاء نموذج واحد (تصنيف أو انحدار) باستخدام Scikit-learn.
3. تقديم رسوم بيانية لتوضيح أداء النموذج.
4. رفع تقرير PDF قصير (1–2 صفحة) يحتوي على النتائج، المقاييس، والتوصيات.
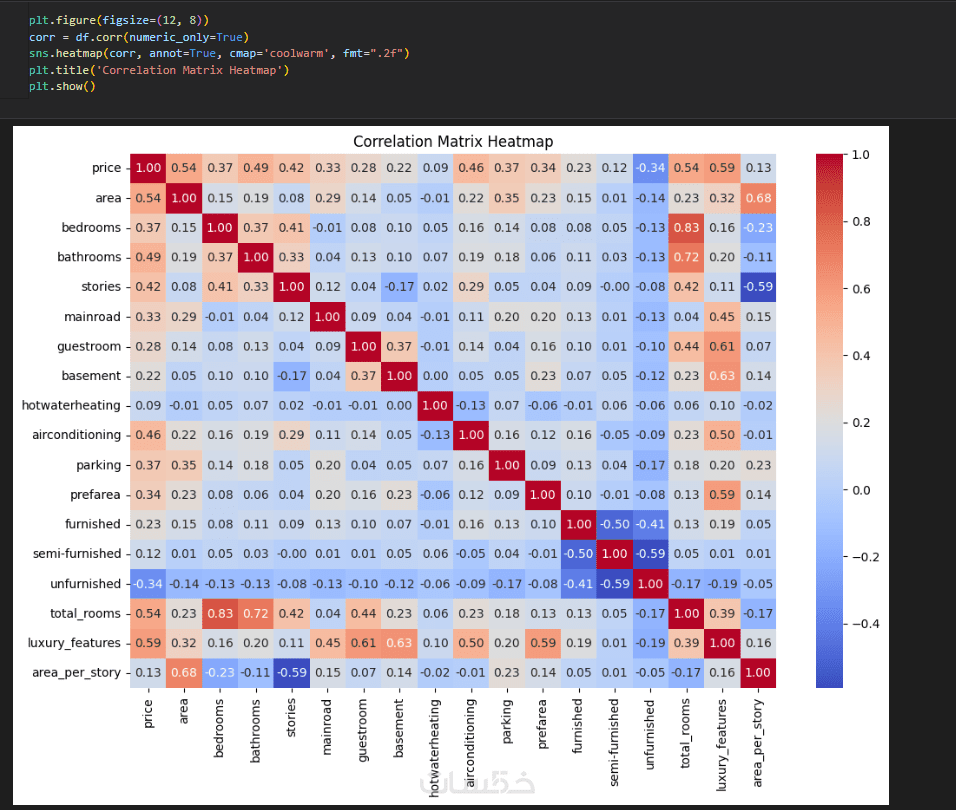
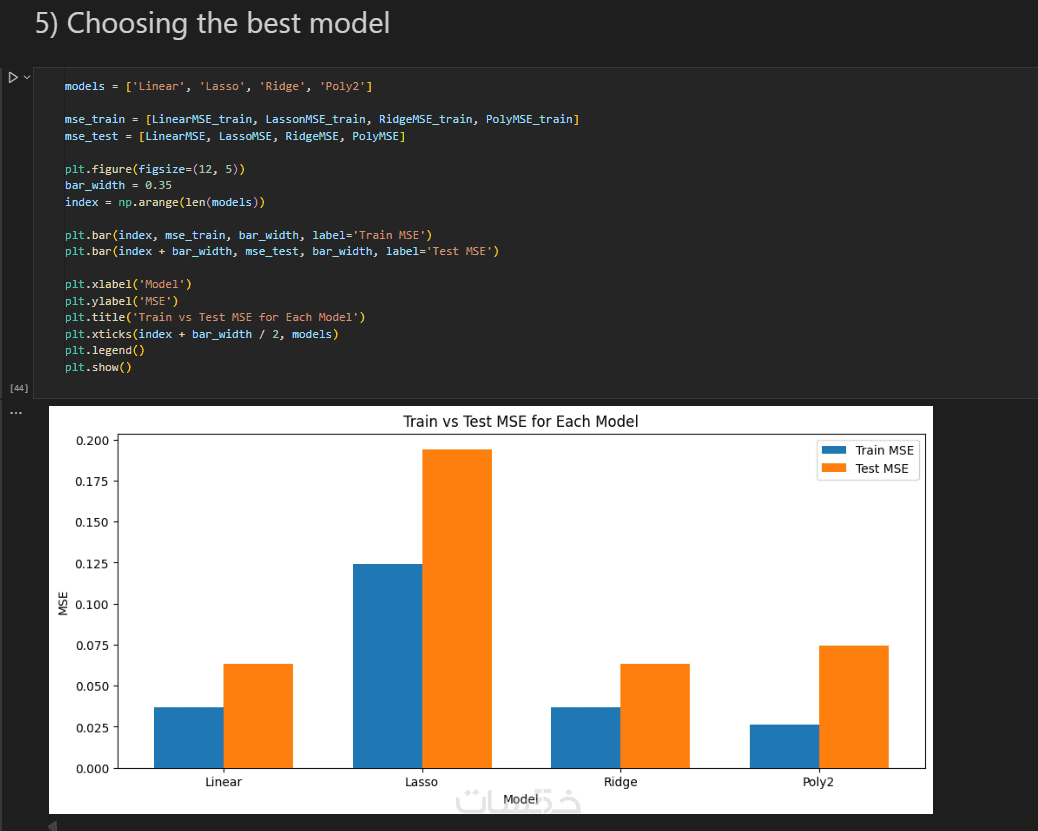
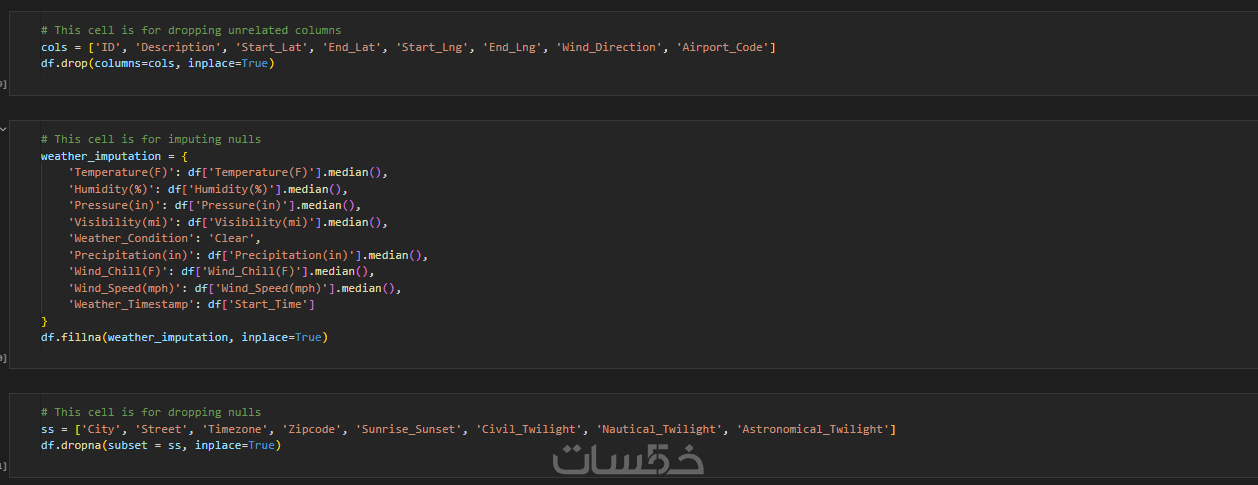
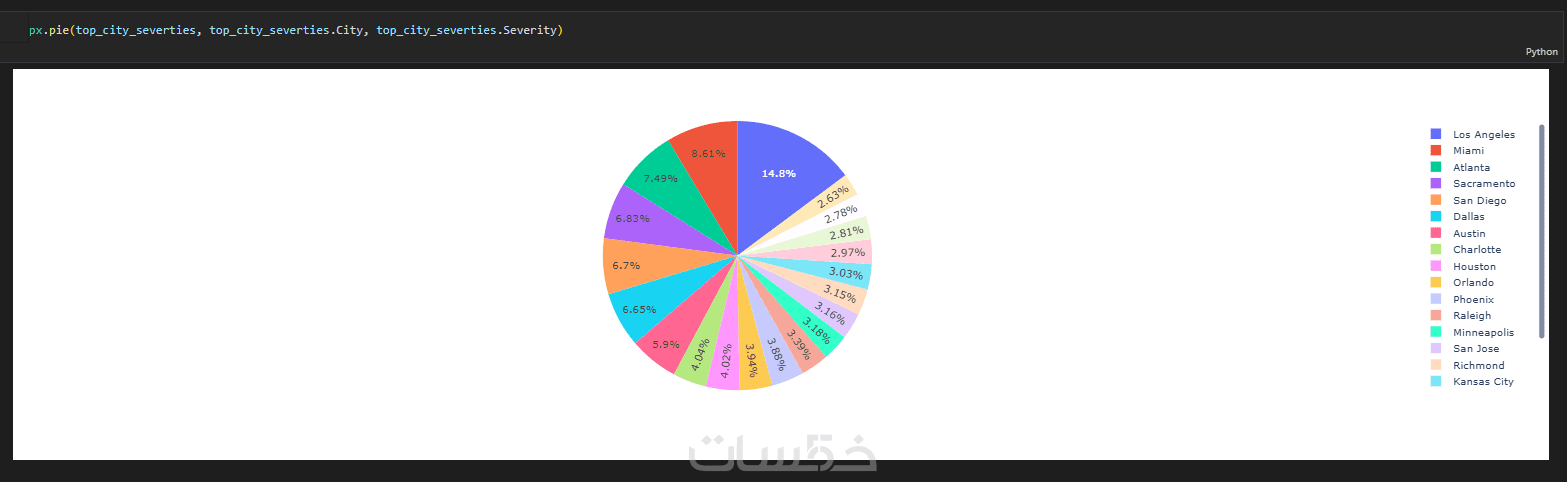
ما الذي ستستلمه
الملفات:
ملف يحتوي على نموذج Machine Learning مدرّب (تصنيف أو انحدار).
الكود كامل منظم داخل Jupyter Notebook أو Python Script.
رسوم بيانية توضّح أداء النموذج والبيانات.
تقرير PDF قصير (1–2 صفحة) يشرح النتائج، المقاييس، والتوصيات.
كلمات مفتاحية
خدمات قد تنال إعجابك





































شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف وتجهيز البيانات
5.00
|
|
زيادة حجم البيانات حتي 50,000 (معالجة و تحليل البيانات الاضافية)
5.00
|
|
تحسين النموذج (Hyperparameter tuning) باستخدام GridSearchCV او RandomSearch
10.00
|
|
بناء نموذج اضافي (تصنيف او انحدار) و المقارنة بين النماذج
5.00
|


شراء الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف وتجهيز البيانات
5.00
|
|
زيادة حجم البيانات حتي 50,000 (معالجة و تحليل البيانات الاضافية)
5.00
|
|
تحسين النموذج (Hyperparameter tuning) باستخدام GridSearchCV او RandomSearch
10.00
|
|
بناء نموذج اضافي (تصنيف او انحدار) و المقارنة بين النماذج
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
