تنظيف و معالجة البيانات Data preprocessing
تنظيف و معالجة البيانات Data preprocessing
وصف الخدمة
جودة النتائج من جودة البيانات! إذا كنت تعاني من بيانات مبعثرة أو قيم مفقودة تعيق مشروعك,سأقوم بـ "صيانة" بياناتك وتجهيزها لتكون وقوداً مثالياً لنماذج التعلم الآلي الخاص بك.
ما سأقوم به بدقة:
التحليل الاستكشافي (EDA): دراسة التوزيع الإحصائي والارتباطات (Correlation) وفهم الأنماط.
تنقية البيانات (Cleaning): معالجة القيم المفقودة (Imputation)، إدارة القيم الشاذة (Outliers)، وتوحيد التنسيقات.
هندسة الخصائص (Feature Engineering): ترميز النصوص (Encoding)، تطبيع المقاييس (Scaling)، واستخلاص ميزات جديدة لرفع دقة التنبؤ.
______________________________________________________
الأدوات: Python (Pandas, NumPy, Scikit-Learn).
مقابل قيمة الخدمة الأساسية، سأقوم بالآتي:
استلام ومعالجة ملف بيانات واحد يحتوي على حتى 5000 صف (Row) كحد أقصى.
مميزات الخدمة
1- تقارير قبل و بعد الخدمة
توضيح للعميل ما هي المشاكل الموجودة في البيانات و ما تم فعله لحلها.
2- تجهيز مخصص للتعلم الآلي (ML-Ready)
أدرك تماماً الفرق بين تنظيف البيانات لغرض "العرض" وتنظيفها لغرض "التدريب". أهيئ لك البيانات بحيث لا تواجه خوارزمياتك مشاكل مثل (Overfitting) أو (Data Leakage) بسبب سوء المعالجة.
3-كود نظيف وقابل لإعادة الاستخدام
أعمل بمبدأ (Scalability)؛ فإذا تغيرت بياناتك مستقبلاً، يمكنني تزويدك بالحلول التي تجعل عملية التنظيف تتكرر آلياً دون الحاجة للبدء من الصفر.
4-بعد نهاية الخدمة اقدم فكرة (اختياري)
ما هي أفضل خوارزميات التعلم الآلي التي تناسب طبيعة بياناتك الحالية.
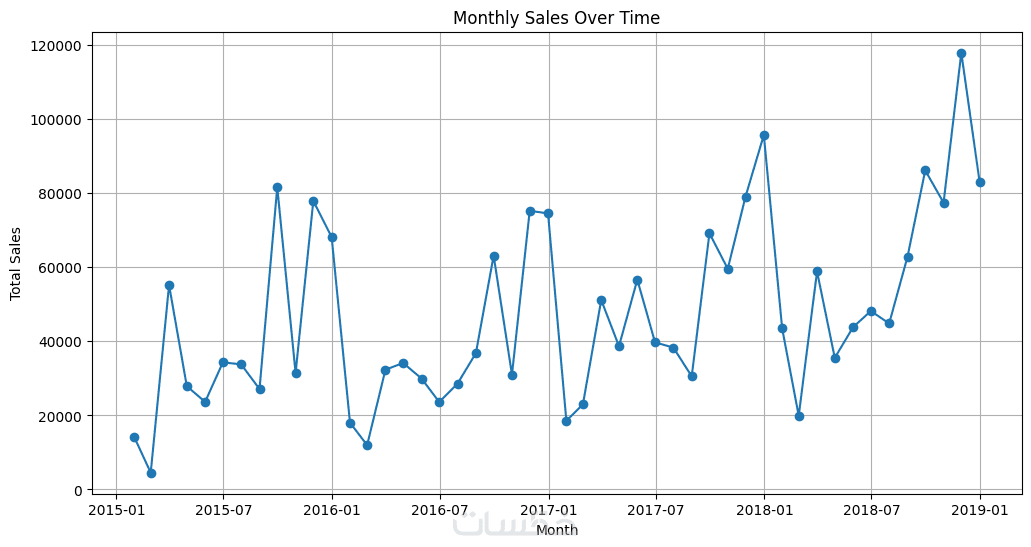
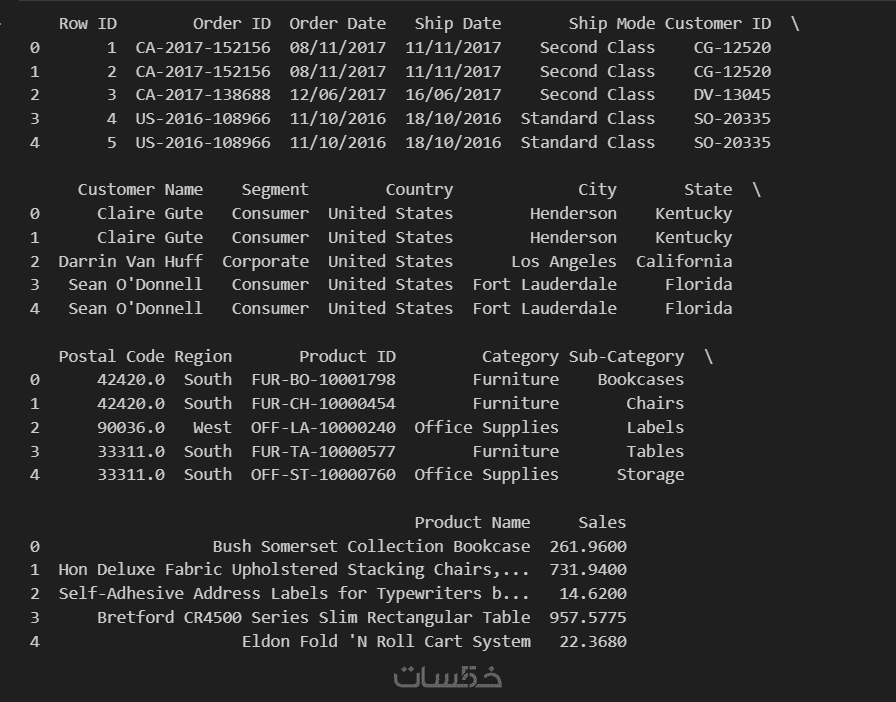
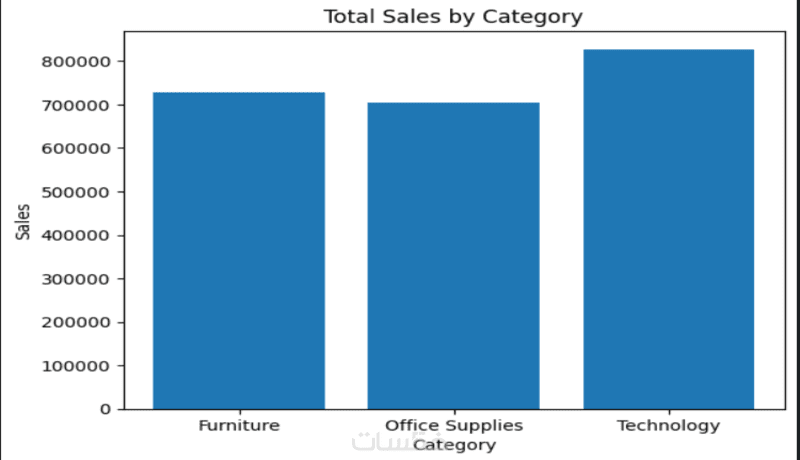
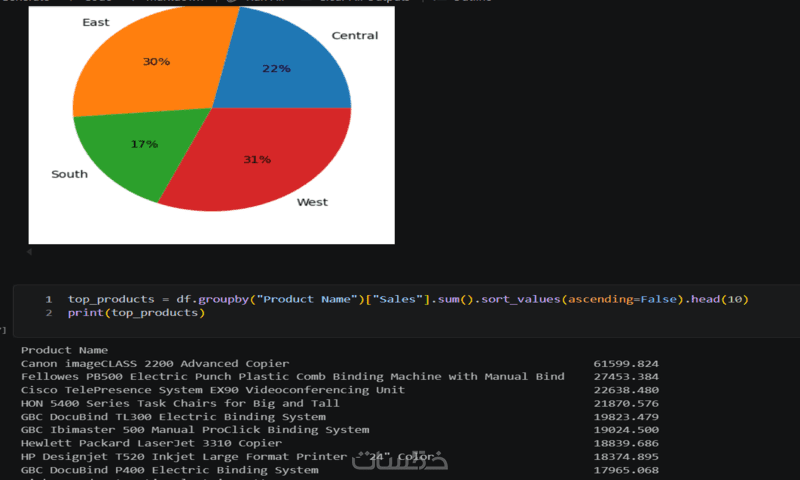
ما الذي ستستلمه
ملف البيانات CSV او Excel.
ملف منظم يحتوي على البيانات بعد معالجتها وتنظيفها بالكامل، جاهز للاستخدام المباشر في أي منصة أخرى.
ملف الأكواد (ipynb)
كود بايثون (Jupyter Notebook) منظم ومشروح بوضوح، يتضمن خطوات استيراد البيانات، التحليل، والعمليات البرمجية المنفذة.
كلمات مفتاحية
خدمات قد تنال إعجابك












شراء الخدمة
سعر الخدمة
$5.00
خدمات قد تنال إعجابك
كلمات مفتاحية

