تنظيف ومعالجة البيانات Data Preprocessing باستخدام Python
تنظيف ومعالجة البيانات Data Preprocessing باستخدام Python
وصف الخدمة
البيانات هي النفط الجديد، لكنها لا تُفيد دون تنظيفها ومعالجتها بالشكل الصحيح.
هل لديك بيانات كبيرة أو غير منظمة تعيق التحليل أو تدريب نماذج الذكاء الاصطناعي؟
أقدم لك خدمة احترافية لتحويل بياناتك الخام إلى بيانات نظيفة ومنظمة وجاهزة للاستخدام عبر بناء Data Pipelines آلية باستخدام Python.
تشمل الخدمة:
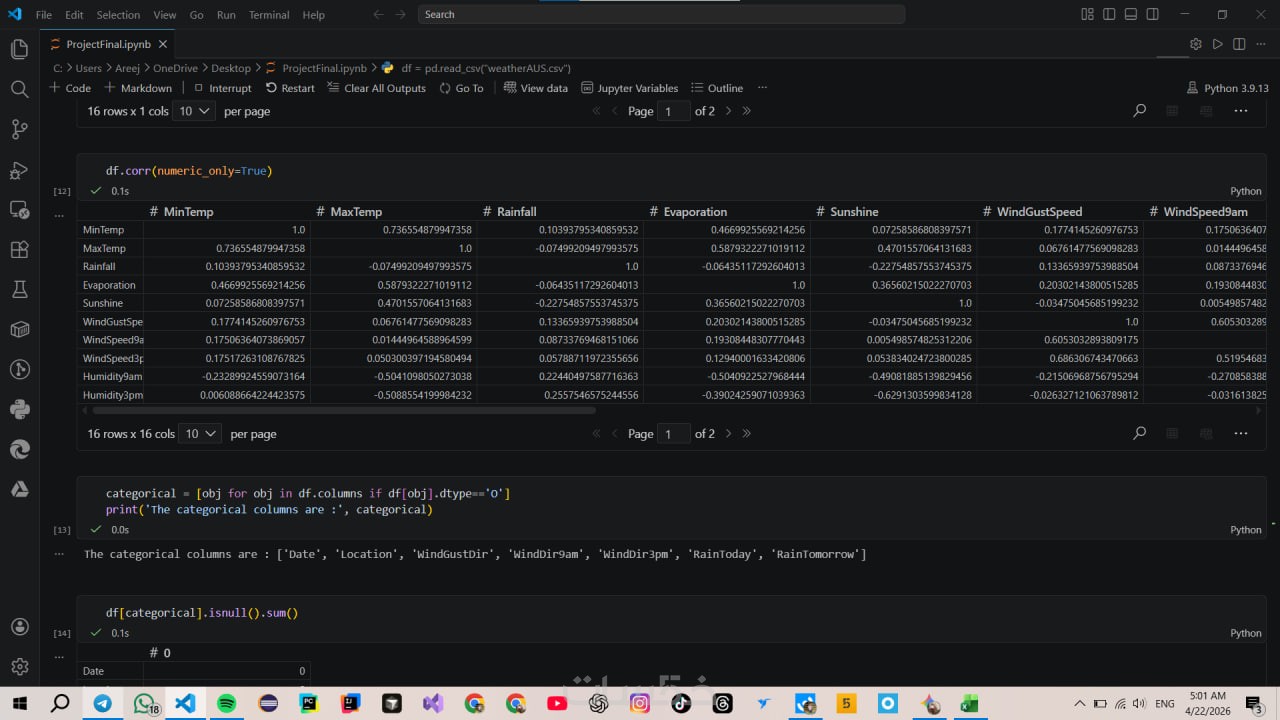
تنظيف البيانات (معالجة القيم المفقودة وإزالة الأخطاء والشوائب)
توحيد وتنسيق البيانات (تواريخ، نصوص، عملات)
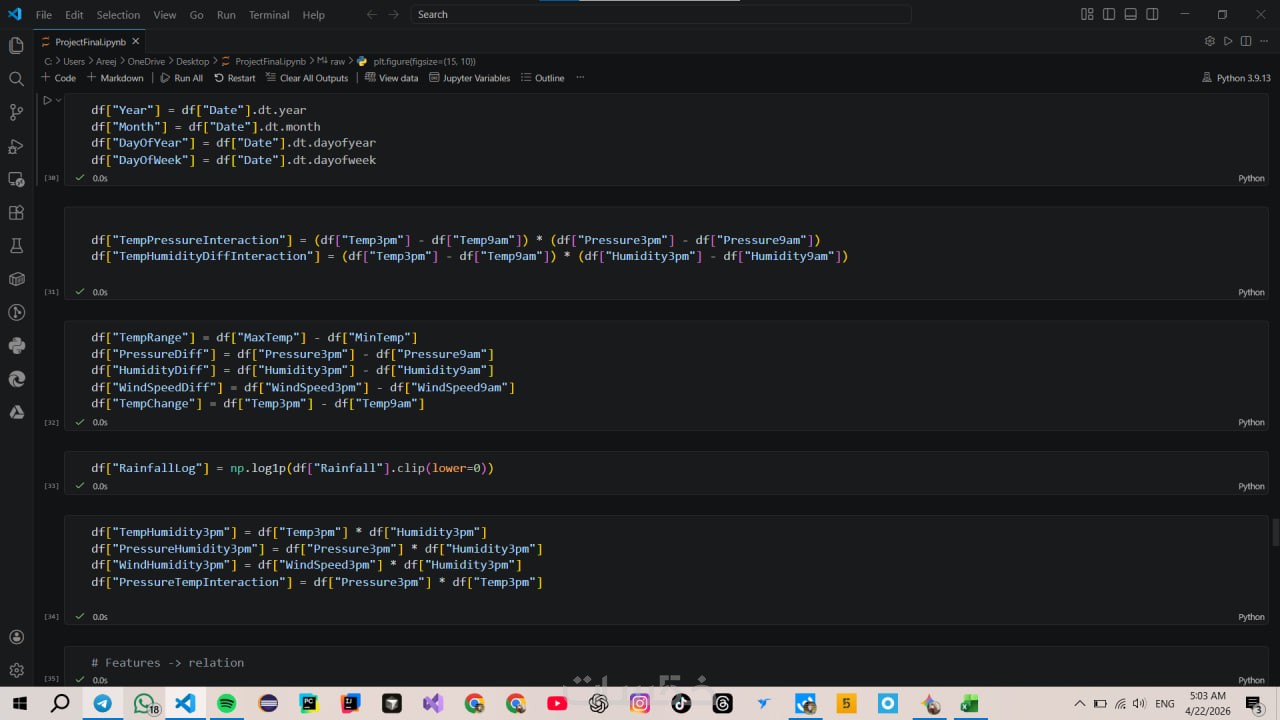
هندسة الميزات وتجهيز البيانات للنمذجة
اكتشاف ومعالجة القيم الشاذة
التعامل مع قواعد البيانات مثل PostgreSQL وربطها بالبايثون
أستخدم أدوات احترافية مثل: Python, Pandas, NumPy, Scikit-learn, SciPy لضمان جودة ودقة عالية في النتائج.
سأحول بياناتك إلى مصدر قوي لاتخاذ القرار وبناء نماذج ذكاء اصطناعي دقيقة وفعالة.
ملاحظات:
(السعر الأساسي) :-
• الخدمة الأساسية تشمل تنظيف ملف واحد بحد أقصى 10,000 صف
• أضمن لك سرية تامة لبياناتك وسيتم حذفها بمجرد تسليم المشروع.
مميزات الخدمة
دقة برمجية متناهية (No Human Error)
العمل لا يتم يدوياً أبداً؛ أستخدم سكريبتات Python ومكتبة Pandas لمعالجة البيانات. هذا يضمن لك دقة بنسبة 100% وانعدام الأخطاء البشرية التي تحدث عادةً عند استخدام الإكسيل التقليدي، مهما كان حجم البيانات ضخماً.
تجهيز احترافي لموديلات الذكاء الاصطناعي (AI-Ready)
أنا لا أقوم بمجرد التنظيف، بل أقوم بـ Feature Engineering. أقوم بتحويل البيانات وتشفيرها (Encoding) وتوحيد مقاييسها (Scaling) بحيث تكون "جاهزة فوراً" للدخول في خوارزميات تعلم الآلة (Machine Learning) دون أي تعديل إضافي منك.
معالجة إحصائية ذكية للقيم المفقودة
بدلاً من حذف البيانات الناقصة وتضييع حجم الداتا، أستخدم أساليب إحصائية متقدمة (مثل Mean/Median/Mode Imputation) لتعويض النقص بذكاء، مما يحافظ على القيمة التحليلية لملفاتك ويضمن دقة النتائج النهائية.
دعم فني وتكامل مع قواعد البيانات
بفضل خبرتي في PostgreSQL و SQL، يمكنني سحب البيانات مباشرة من قواعد بياناتك أو تصديرها إليها بعد التنظيف، مع تقديم "تقرير جودة" (Quality Report) يوضح لك حالة البيانات قبل وبعد المعالجة لتكون على دراية كاملة بكل تغيير تم.
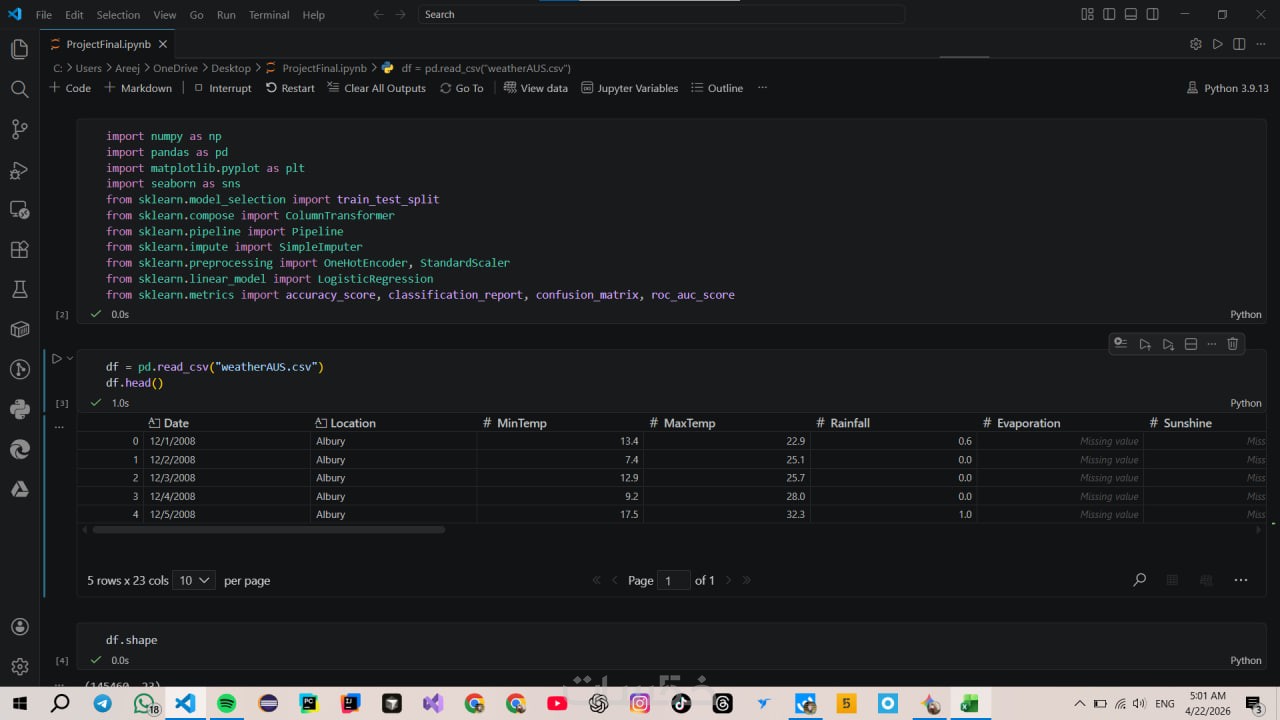
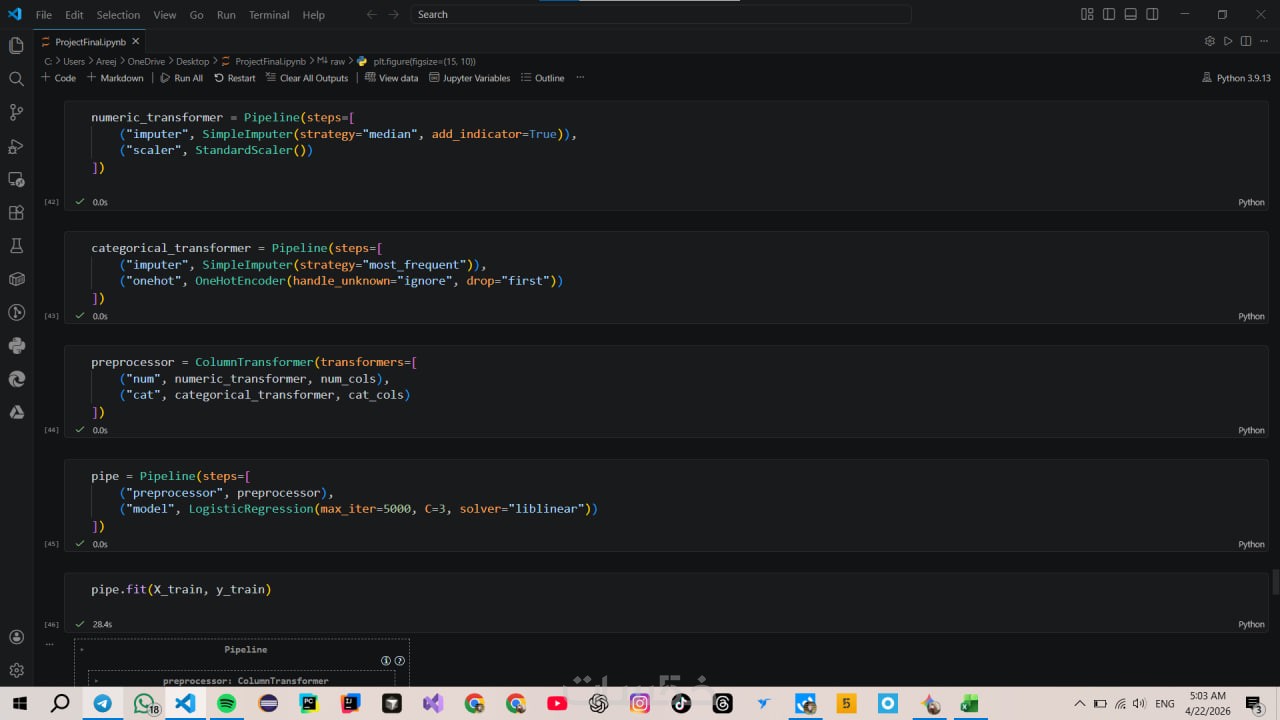
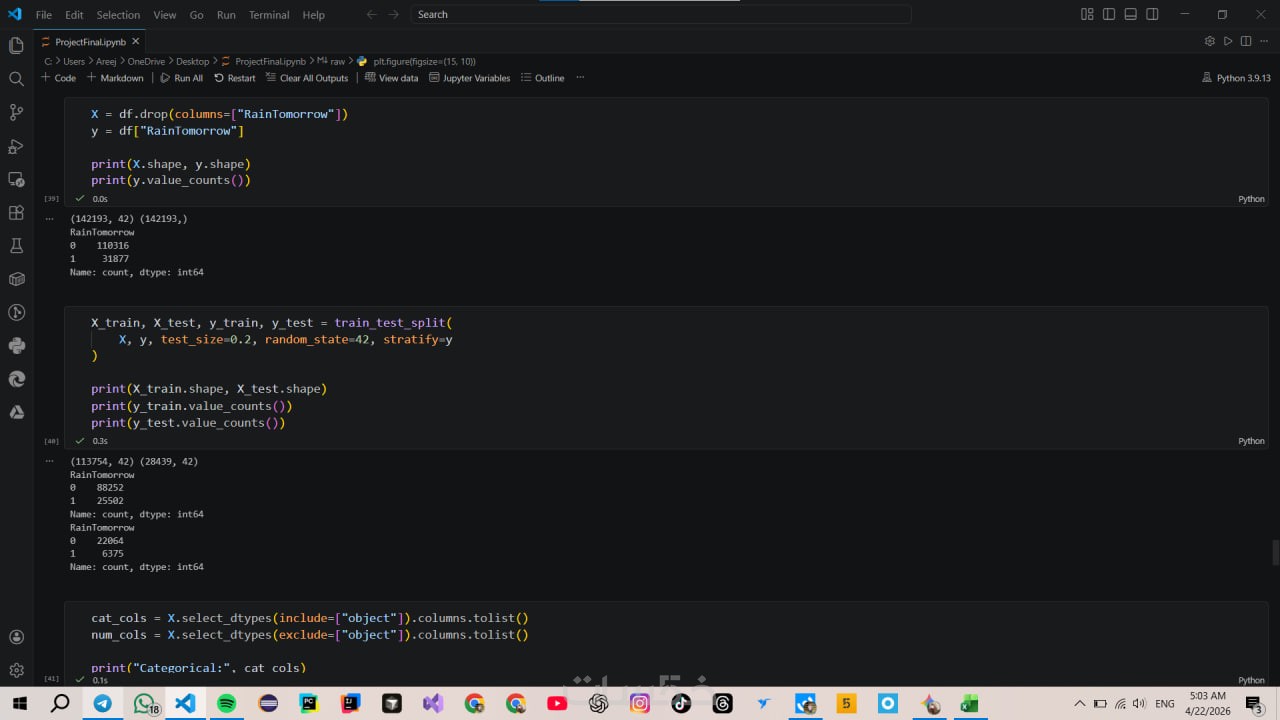
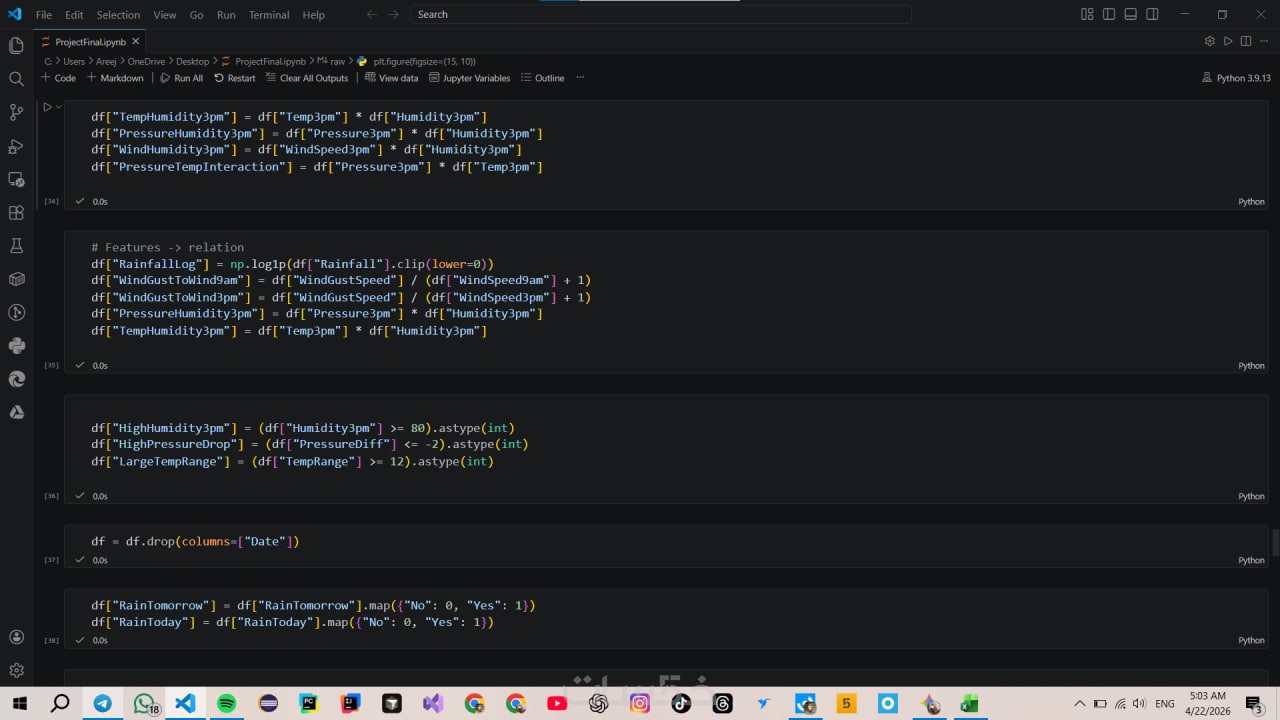
ما الذي ستستلمه
تجهيز البيانات للشبكات العصبية (Deep Learning Ready)
أقوم بتجهيز الـ Arrays والـ Tensors وتصحيح أبعاد البيانات لتكون متوافقة تماماً مع تدريب النماذج العميقة (ANN, DNN). أضمن لك أن تكون البيانات مهيأة للـ Input Layer مباشرة دون أي أخطاء في الـ Matrix Dimensions.
معالجة وتحسين بيانات الصور (Computer Vision Preprocessing)
بفضل خبرتي في الـ CNN، أقدم خدمة تجهيز صور التدريب؛ بدءاً من توحيد الأحجام (Resizing)، والـ Normalization لقيم البكسلات، وصولاً إلى الـ Data Augmentation، لضمان أعلى دقة لموديلات الرؤية الحاسوبية الخاصة بك.
تجزئة البيانات ذكياً (Advanced Clustering & Segmentation)
لا أكتفي بالتنظيف، بل أستخدم خوارزميات التجميع (Clustering) مثل K-Means لتقسيم بياناتك إلى مجموعات ذات خصائص متشابهة، مما يساعدك في اكتشاف الأنماط الخفية في بيانات العملاء أو المنتجات قبل البدء في تحليلها.
تطبيق تقنيات الـ Transfer Learning في المعالجة
أفهم جيداً متطلبات الموديلات العالمية (Pre-trained Models). أقوم بتجهيز بياناتك لتناسب متطلبات هذه الموديلات من حيث التنسيق وتوزيع البيانات، مما يقلل من وقت التدريب (Training Time) ويحسن النتائج النهائية لمشروعك.
الالتزام بمعايير مشاريع التخرج الاحترافية
بما أنني أتعامل مع مناقشات مشاريع التخرج (Graduation Projects)، فأنا أطبق أعلى معايير الجودة والتوثيق (Documentation). ستحصل على كود نظيف، مرتب، ومشروح بالكامل، مما يجعل عملي قابلاً للدمج في أكبر المشاريع الأكاديمية والتجارية.
كلمات مفتاحية
خدمات قد تنال إعجابك












طلب الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف ومعالجة بيانات ضخمة تصل اي 20,000 سجل/صف مع ضمان الدقة البرمجية الكاملة
5.00
|
|
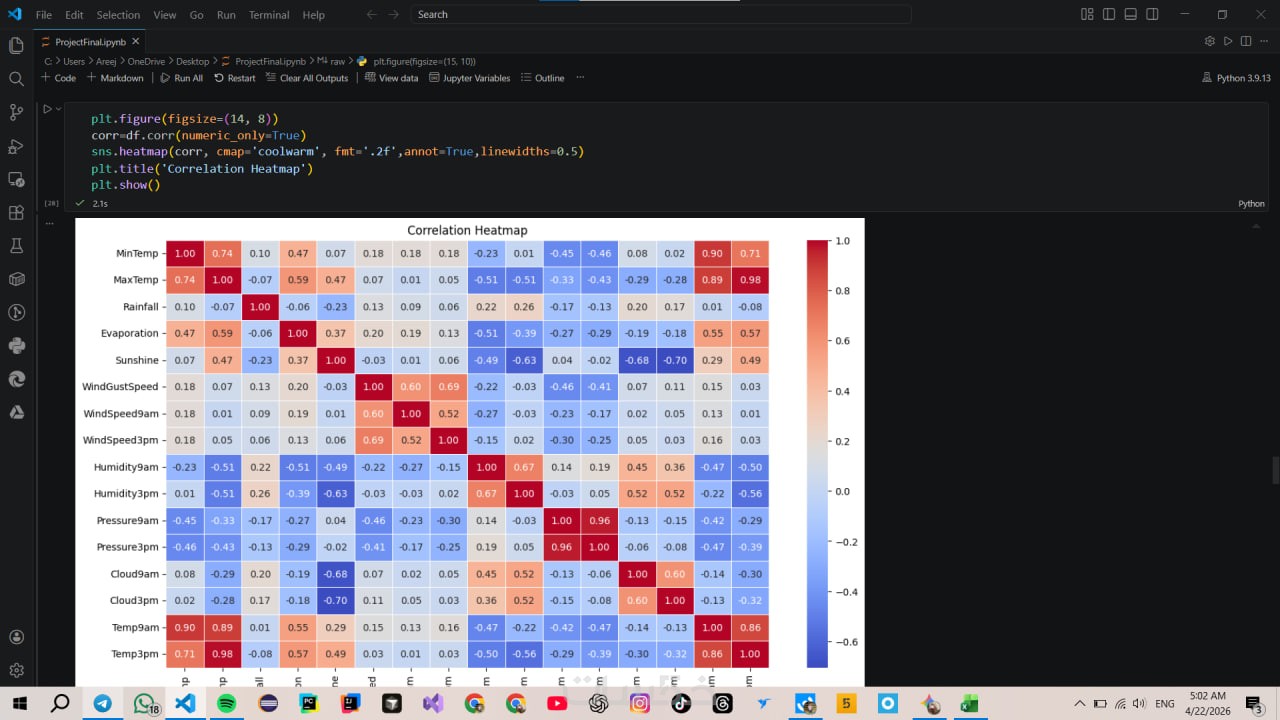
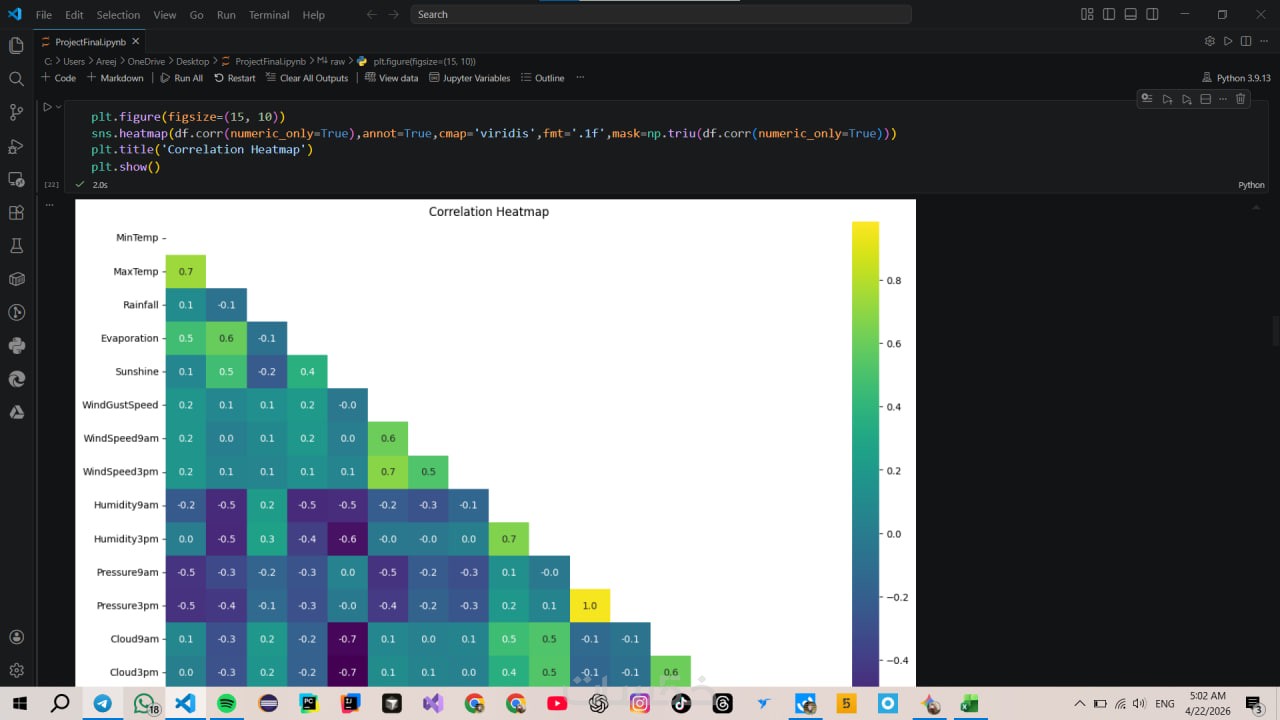
تقرير احترافي برسومات بيانية (Matplotlib- Seaborn) توضح توزيع البيانات، الارتباطات بين المتغيرات
5.00
|
|
تجهيز البيانات كليا للموديلات (Scaling- Encoding) للموديلات لضمان أعلي دقة ف النتائج
10.00
|


طلب الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
تنظيف ومعالجة بيانات ضخمة تصل اي 20,000 سجل/صف مع ضمان الدقة البرمجية الكاملة
5.00
|
|
تقرير احترافي برسومات بيانية (Matplotlib- Seaborn) توضح توزيع البيانات، الارتباطات بين المتغيرات
5.00
|
|
تجهيز البيانات كليا للموديلات (Scaling- Encoding) للموديلات لضمان أعلي دقة ف النتائج
10.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
