تحليل بيانات العملاء والمبيعات باستخدام Python و Jupyter Notbook
تحليل بيانات العملاء والمبيعات باستخدام Python و Jupyter Notbook
وصف الخدمة
هذا المشروع يركز على تحليل بيانات العملاء والمبيعات باستخدام Python في بيئة Jupyter Notebook. تم استخدام مكتبات Pandas و NumPy لمعالجة البيانات وإجراء التحليلات الإحصائية. شمل المشروع الخطوات التالية:
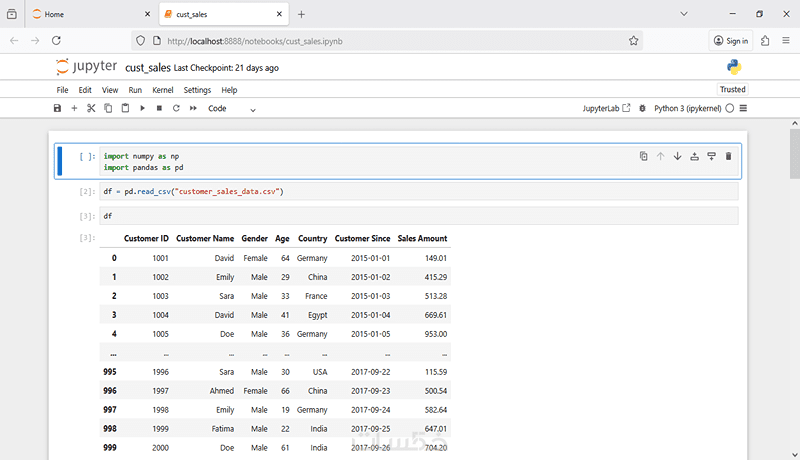
• استيراد البيانات وتحميلها للبدء في التحليل.
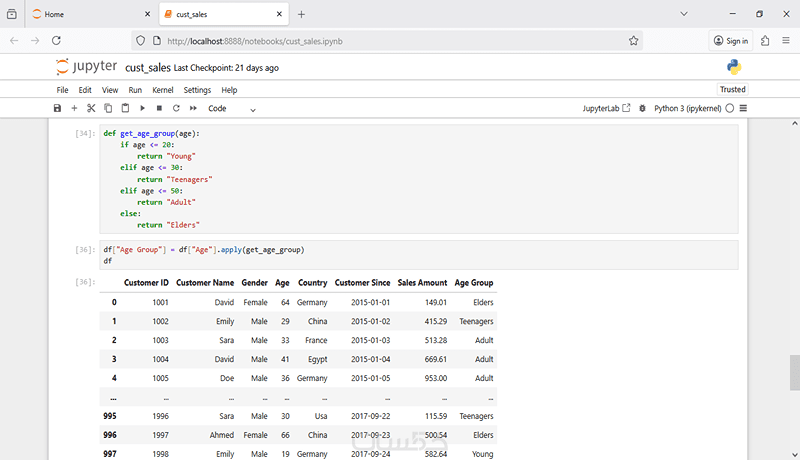
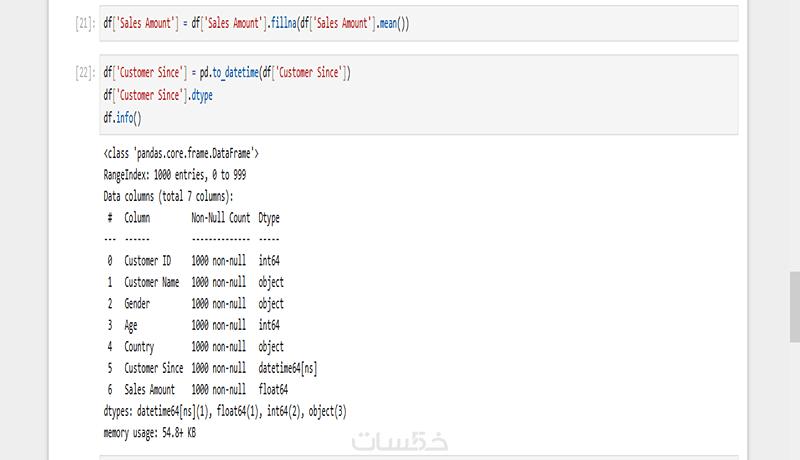
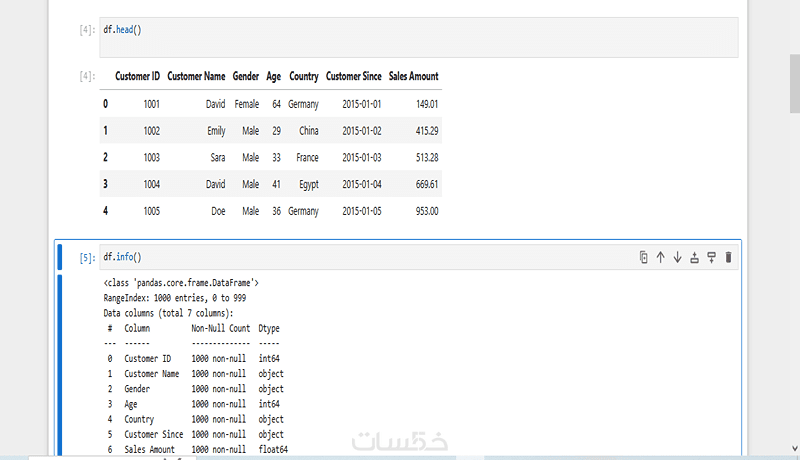
• استخدام info() للحصول على نظرة عامة على البيانات، مثل نوع كل عمود وعدد القيم غير الفارغة.
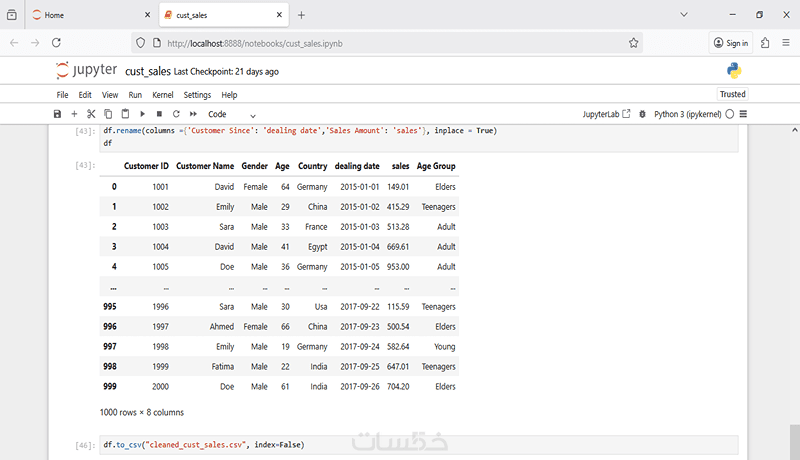
• إعادة تسمية الأعمدة لتسهيل التعامل مع البيانات.
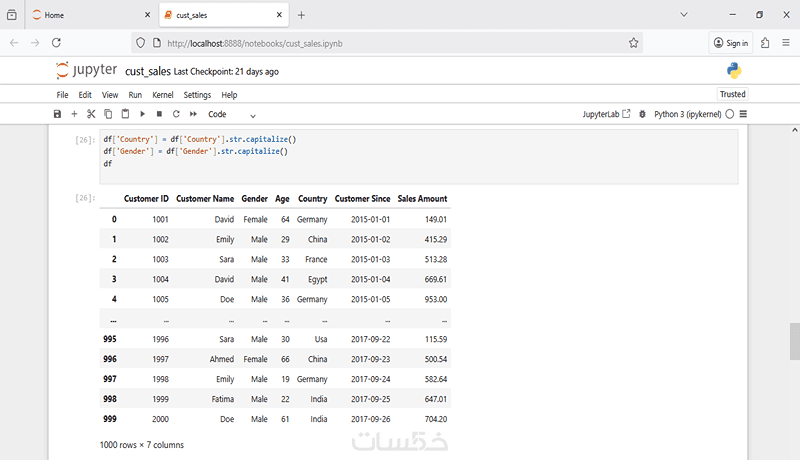
• التعامل مع القيم المكررة وحذفها لضمان دقة التحليل.
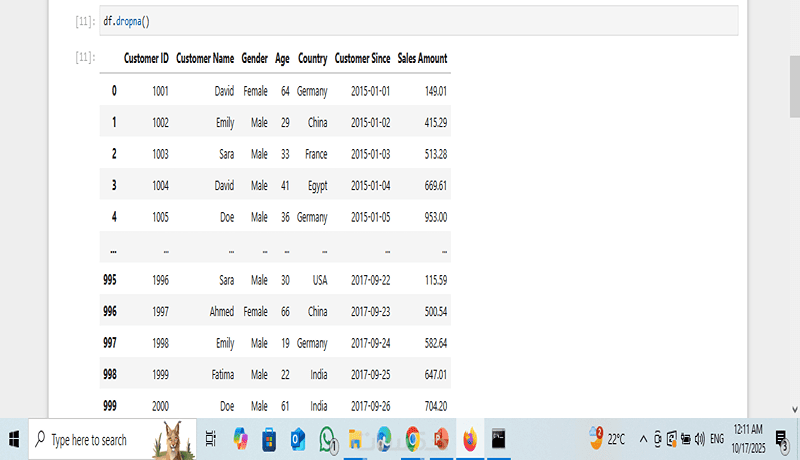
• حذف القيم الفارغة (Dropna) لتحسين جودة البيانات.
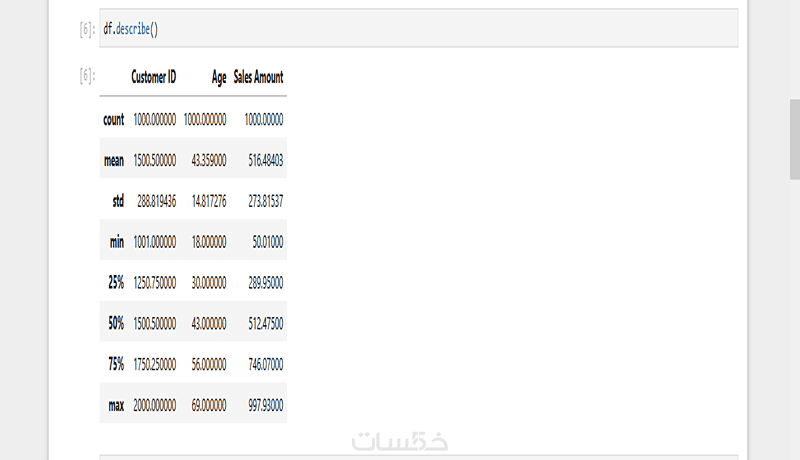
• تحليل إحصائي للبيانات باستخدام describe() للحصول على معلومات مثل المتوسط والانحراف المعياري والحدود القصوى والدنيا.
• حساب عدد القيم الفريدة لكل عمود باستخدام nunique() لفهم تنوع العملاء والمنتجات.
• تصدير البيانات النظيفة والمحسوبة إلى ملف CSV للاستخدام المستقبلي أو لمشاركة النتائج بسهولة.
حجم الخدمة المقدمة عبارة عن 10 اعمدة يتم استخراج منهم المعلومات المطلوبة
مميزات الخدمة
مميزات الخدمة اللى هقدمها لحضرتك تشمل :
تنظيف شامل للبيانات وحذف القيم المكررة والفارغة لضمان دقة التحليل.
• تحليل إحصائي كامل باستخدام describe() للحصول على رؤى دقيقة حول البيانات.
• تحديد عدد القيم الفريدة لكل عمود باستخدام nunique() لفهم تنوع العملاء والمنتجات.
• تصفية وترتيب البيانات (Filter و Sort) للحصول على معلومات دقيقة حسب احتياجات العمل.
• تجميع البيانات (Group By) للحصول على تقارير مفصلة عن المبيعات والعملاء حسب الفئات.
• تصدير البيانات النهائية إلى ملف CSV جاهز للاستخدام المستقبلي أو لمشاركة النتائج بسهولة.
ما الذي ستستلمه
اللى حضرتك هتستلمه منى عبارة عن :
• ملف Jupyter Notebook يحتوي على جميع الأكواد والخطوات المنفذة.
• نسخة CSV من البيانات بعد التنظيف والتحليل.
• تقرير مختصر بالنتائج الإحصائية الرئيسية والملاحظات الهامة عن العملاء والمبيعات.
كلمات مفتاحية
خدمات قد تنال إعجابك












طلب الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
التنبيه عن البيانات غير الطبيعية و تفسير النتائج بشكل مبسط
5.00
|
|
حجم الاعمدة (10-20)
5.00
|


طلب الخدمة
سعر الخدمة
$5.00
تطويرات اختيارية
التنبيه عن البيانات غير الطبيعية و تفسير النتائج بشكل مبسط
5.00
|
|
حجم الاعمدة (10-20)
5.00
|
خدمات قد تنال إعجابك
كلمات مفتاحية
